




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
يتطلب نشر الذكاء الاصطناعي التوليدي على منصة جوجل السحابية (GCP) تنسيق مجموعة معقدة من العناصر الأساسية: محرك جوجل كوبيرنيتيس (GKE)، وحدات معالجة الموتر السحابية (Cloud TPUs)، و Vertex AI. بينما توفر GCP قوة الحوسبة الخام، فإن ربط هذه المكونات بمنصة مطور داخلية (IDP) متوافقة يتطلب هندسة مخصصة كبيرة.
تعمل TrueFoundry كطبقة بنية تحتية علوية. نحن نتولى التنسيق، مما يترك لك التحكم في شبكة VPC وموقع البيانات. توضح هذه المقالة أنماط تكاملنا مع GCP، وتحديداً فيما يتعلق ببنية المستوى المنفصل، اتحاد هوية عبء العمل، وإدارة وحدات معالجة الموتر (TPU).
نستخدم بنية المستوى المنفصل لعزل واجهة الإدارة عن بيئة تنفيذ عبء العمل الخاصة بك.
حدود الأمان لا نطلب قواعد جدار حماية واردة. يبدأ الوكيل في مجموعتك تدفق WebSocket أو gRPC آمنًا وصادرًا فقط إلى مستوى التحكم لدينا. يستعلم عن بيانات نشر التطبيقات ويدفع بيانات القياس عن بعد. تظل شبكة VPC الخاصة بك خاصة بحركة المرور الواردة الخارجية.
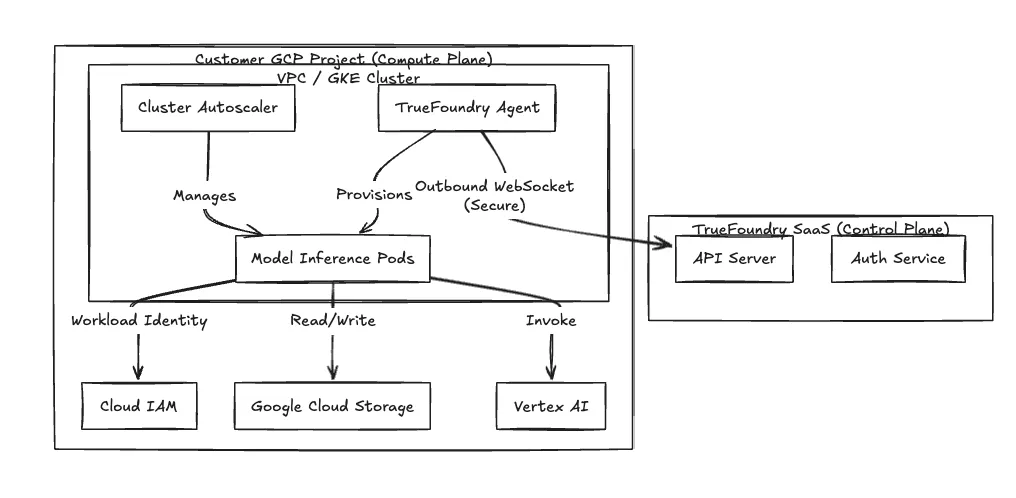
الشكل 1: بنية المستوى المنفصل تعزل معالجة البيانات داخل شبكة VPC الخاصة بالعميل.
لتحقيق أداء عالٍ، نقوم بتهيئة مستوى الحوسبة لاستخدام مجموعات VPC الأصلية باستخدام عناوين IP البديلة. جميع موارد الحوسبة توجد ضمن الشبكات الفرعية الخاصة.
الدخول (طلبات الاستدلال) تدخل حركة مرور التطبيق شبكة VPC عبر موازنة حمل السحابة (عادةً ما يكون ALB خارجيًا عالميًا). يقوم ALB بإنهاء TLS ويعيد توجيه الطلبات إلى بوابة دخول Istio التي تعمل ضمن مجموعة GKE.
الوصول الخاص إلى Google للحفاظ على الامتثال، يتم توجيه حركة المرور إلى واجهات برمجة تطبيقات Google (مثل Cloud Storage و Vertex AI) عبر الوصول الخاص إلى Google. هذا يحافظ على حركة المرور بين وحدات الاستدلال وخدمات GCP المدارة على العمود الفقري لشبكة Google، متجاوزة الإنترنت العام.
الخروج تتطلب عقد عامل GKE وصولاً خارجيًا لسحب صور الحاويات من سجل البيانات الاصطناعية. نقوم بتوجيه حركة المرور هذه عبر Cloud NAT متصلة بالشبكات الفرعية الخاصة.
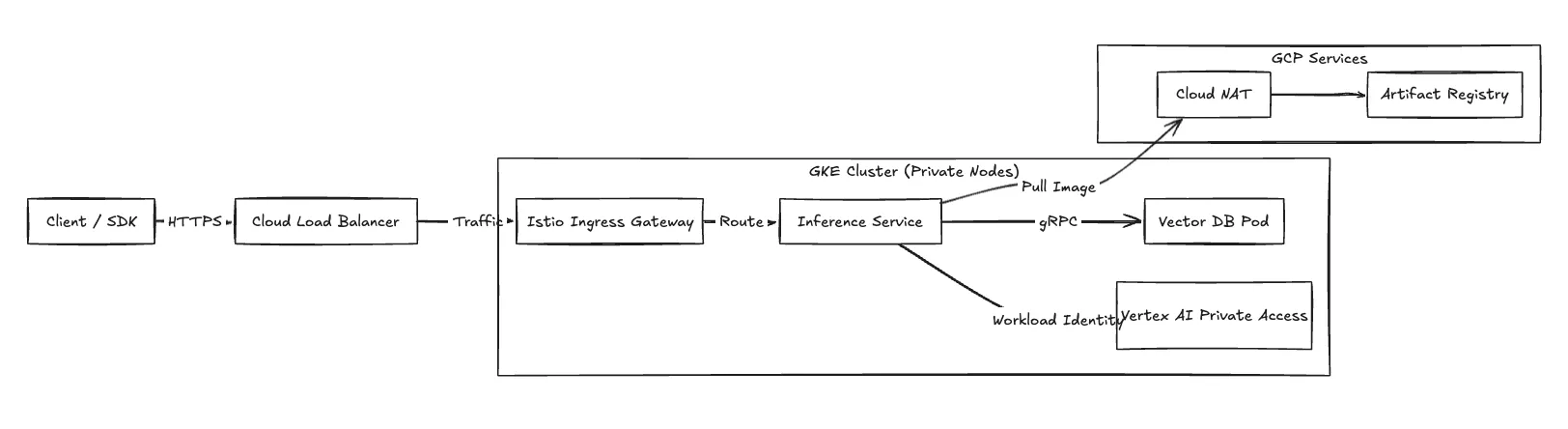
الشكل 2: تدفق حركة مرور الشبكة يوضح الاتصال الوارد والخاص.
نفرض إزالة مفاتيح حساب الخدمة الثابتة (ملفات .json). TrueFoundry تطبق هوية عبء عمل GKE لجميع مصادقة أعباء العمل.
تسلسل المصادقة
إذا تم اختراق pod، فإن نطاق الضرر يقتصر بشكل صارم على أدوار IAM الممنوحة لحساب GSA المحدد هذا.
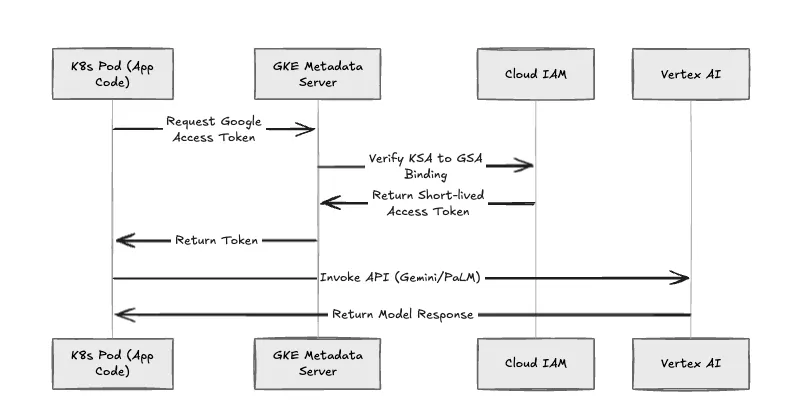
الشكل 3: تدفق مصادقة هوية عبء عمل GKE.
نتكامل مع تجمعات عقد GKE لتنسيق وحدات معالجة الرسوميات NVIDIA ووحدات معالجة الموتر السحابية.
تنسيق TPU تتطلب الجدولة على وحدات معالجة الموتر (TPUs) التعامل مع قيود طوبولوجيا محددة. تدير TrueFoundry محدد العقد (nodeSelector) والتسامحات (tolerations) اللازمة لجدولة الحاويات (pods) على شرائح TPU (مثل v4-8، v5e). نقوم تلقائيًا بحقن برامج التشغيل الضرورية وحدود الموارد في بيان النشر، مما يجرّد إعداد Kubernetes منخفض المستوى.
إدارة Spot VM لأعباء عمل المعالجة الدفعية أو التطوير، نقوم بإدارة أجهزة Spot الافتراضية لتقليل التكاليف (عادةً 60-90% مقارنةً بالطلب الفوري).
تتسبب إدارة مفاتيح مميزة لنماذج مثل Gemini Pro في زيادة الأعباء التشغيلية. توفر TrueFoundry بوابة ذكاء اصطناعي تعمل كواجهة برمجة تطبيقات (API) موحدة.
يتيح هذا التكامل لفريقك الاستفادة الكاملة من مزايا أجهزة GCP — وتحديداً وحدات معالجة الموتر (TPUs) والشبكات عالية الإنتاجية — دون الانغماس في التعقيدات التشغيلية لإدارة Kubernetes الخام. تعمل TrueFoundry كمضاعف قوة لبنيتك التحتية: نحن نجرد تعقيد تنسيق GKE بينما تحتفظ أنت بالسلطة المطلقة على الأمن وموقع البيانات. يتيح لك هذا التوازن تشغيل أعباء عمل الذكاء الاصطناعي التوليدي (GenAI) على الفور، محولاً البنية التحتية من قيد إلى ميزة سرعة تنافسية.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
