




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
For cloud architects and DevOps engineers, the primary challenge in scaling Generative AI is often not the availability of compute resources, but the orchestration of those resources. AWS provides powerful primitives -- Amazon EKS, Spot Instances, IAM roles, and Amazon Bedrock. However, combining these into a cohesive internal developer platform often involves complex configuration and ongoing maintenance.
TrueFoundry acts as that orchestration layer, sitting as an infrastructure overlay directly inside your AWS account. Below, we’ll break down exactly how the platform integrates with AWS—covering security boundaries, identity federation, networking, and compute optimization.
We use a split-plane architecture to decouple management from execution.
Connectivity relies on a secure, outbound-only WebSocket or gRPC stream. The agent running in your cluster initiates the connection to the Control Plane to fetch new deployment manifests and push status updates (like pod health). Because the traffic is outbound-only, you don’t need to open any inbound ports on your VPC security groups—keeping your VPC completely private.
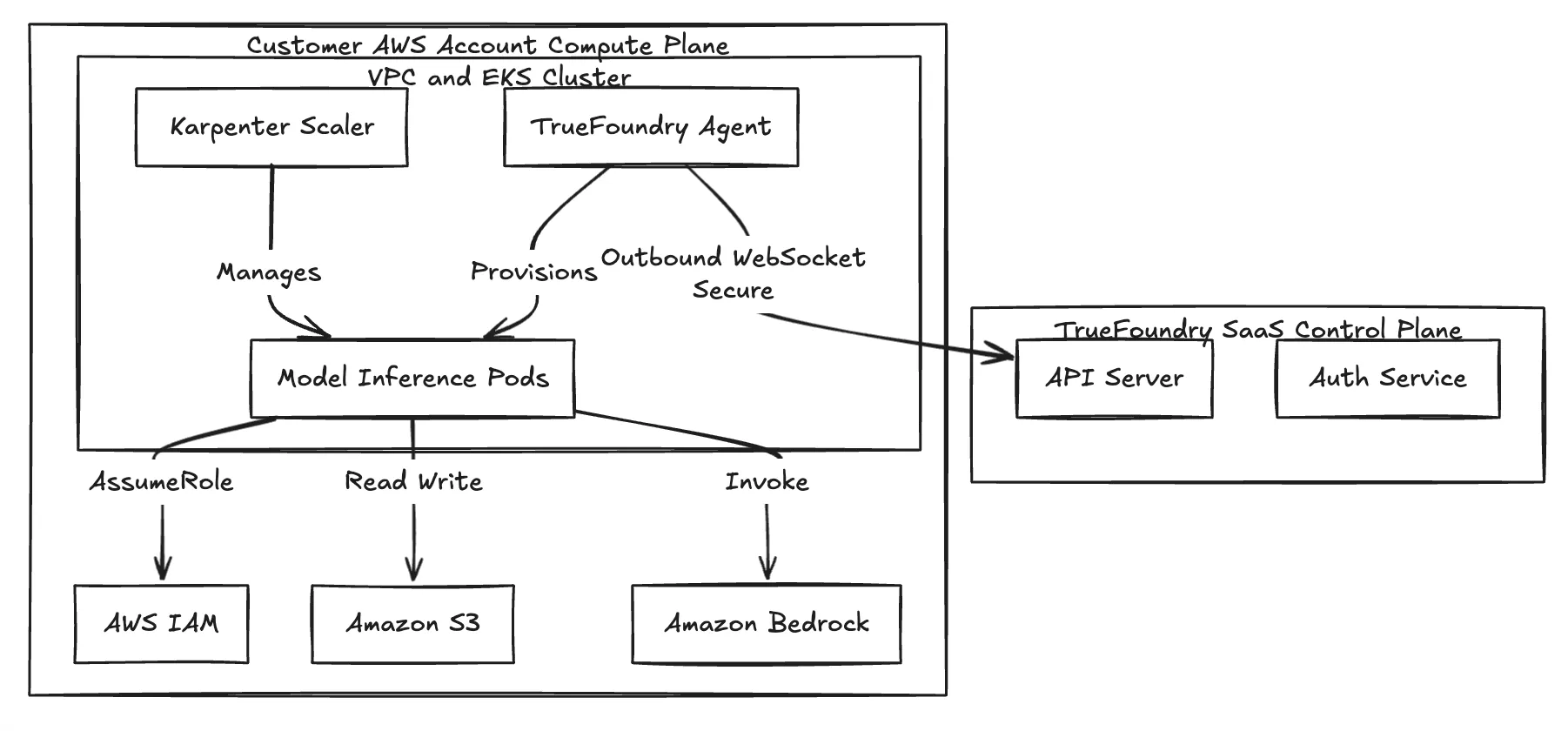
Fig 1: The Split-Plane Architecture ensures data residency remains within the customer VPC.
When deploying TrueFoundry into an AWS environment, the networking configuration leverages the AWS VPC CNI plugin for Kubernetes. Compute resources operate within private subnets, ensuring that inference endpoints are not exposed to the public internet by default.
TrueFoundry deploys Istio to manage east-west traffic between microservices. For example, in a RAG pipeline where an embedding service communicates with a vector database, Istio manages routing and enforces mutual TLS (mTLS). This ensures internal cluster traffic is encrypted in transit without requiring application-level changes.
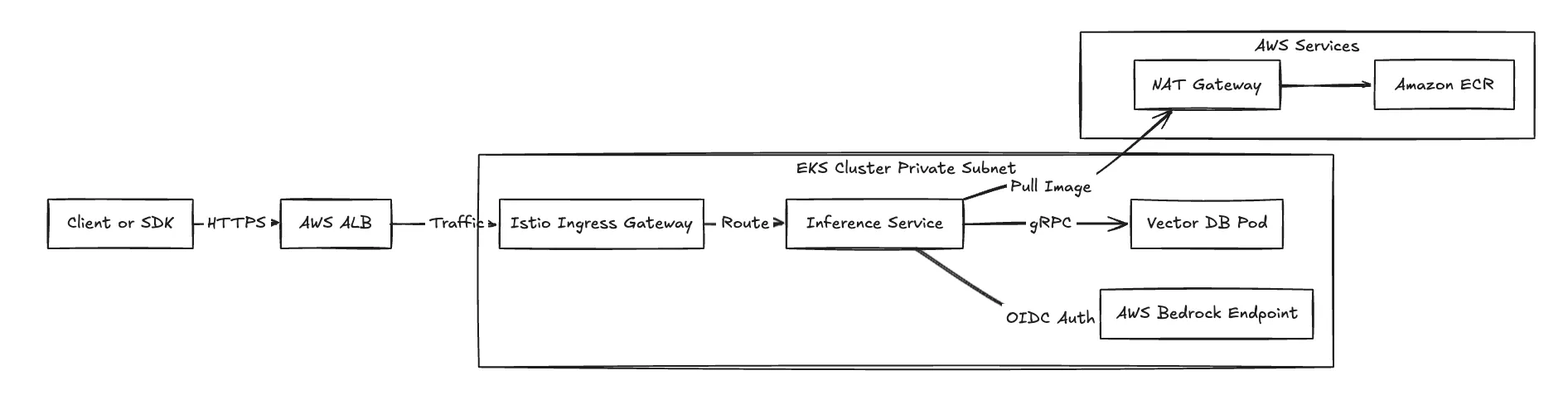
Fig 2: Network traffic flow demonstrating ingress for inference and egress for dependencies.
A primary security objective in enterprise AWS environments is the removal of static credentials. TrueFoundry addresses this by implementing IAM Roles for Service Accounts (IRSA).
When a user deploys a workload, such as a fine-tuning job or an inference service, the platform executes the following workflow:
This mechanism ensures application code uses standard AWS SDKs (e.g., boto3) without hardcoded secrets. If a pod is compromised, the potential impact is limited to the specific permissions granted to that IAM role, and credentials automatically expire.
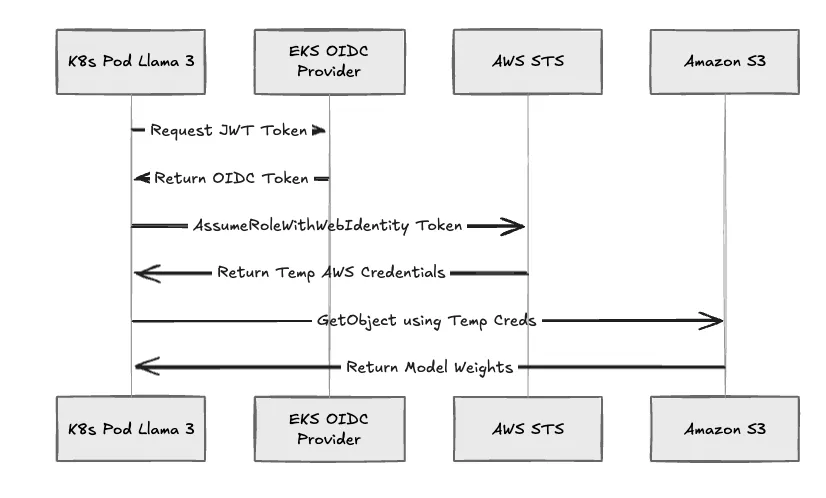
Fig 3: The IRSA authentication flow used by TrueFoundry workloads.
Running Large Language Models (LLMs) on on-demand instances presents significant cost challenges. TrueFoundry orchestrates Karpenter, the open-source Kubernetes node provisioning system, to optimize compute utilization.
TrueFoundry provides specialized logic for managing EC2 Spot Instances:
This orchestration enables the reliable use of Spot Instances for production inference workloads, typically yielding savings of up to 70% compared to On-Demand pricing for spot-tolerant workloads.
For organizations utilizing proprietary models, TrueFoundry serves as a unified API interface for Amazon Bedrock and Amazon SageMaker.
Rather than embedding direct AWS SDK calls within application code, developers route requests through the TrueFoundry Gateway. The Gateway performs:
This centralization allows administrators to manage access policies at the Gateway level without constantly modifying IAM policies or rotating AWS credentials.
TrueFoundry supports deploying models to SageMaker endpoints. However, the platform also provides the capability to deploy models directly to EC2/EKS. This alternative allows organizations to bypass the premiums typically associated with fully managed inference endpoints while maintaining a consistent deployment experience for the developer.
TrueFoundry is designed to integrate with existing Infrastructure as Code workflows. The platform provides verified Terraform Modules لتوفير البنية التحتية الأساسية المطلوبة:
يضمن هذا أن البيئة تتكون من موارد AWS قياسية محددة في ملف حالة Terraform الخاص بالعميل، مما يجعلها قابلة للتدقيق بالكامل.
يوضح الجدول التالي الاختلافات التشغيلية بين بناء منصة باستخدام أساسيات AWS الخام مقابل استخدام طبقة TrueFoundry.
يتوافق دمج TrueFoundry مع AWS مع النمط المعماري لاستخدام المزود السحابي الضخم لموثوقية البنية التحتية، مع تطبيق مستوى تحكم متخصص للإدارة الخاصة بالتطبيقات.
بالنسبة للمؤسسات التي تستثمر في AWS، يوفر هذا النموذج آلية لتحديث عمليات الذكاء الاصطناعي مع الحفاظ على إقامة البيانات الحالية ومحيطات الأمان. يحتفظ العميل بالتحكم في VPC وحدود الأمان، باستخدام TrueFoundry لتبسيط تعقيد دورة حياة تطبيق الذكاء الاصطناعي.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
