




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
50 Questions to Ask Every Vendor in 2026
Enterprise AI platform evaluations fail in predictable ways. The vendor's demo runs against a curated test prompt. Their pricing slide uses 5,000-token-per-call assumptions that don't match your actual workload. The security architecture diagram they show is for a deployment mode you haven't asked about. The MCP capability they claim is available “in our next release.” Six weeks later you're signing a contract for a product that's a 70 percent fit, and your platform team spends the contract term filling the other 30 percent with custom work.
A scored RFP changes the dynamic. Every vendor answers the same questions, in writing, before any demo runs. Their non-answers (a question dodged, a capability that “requires our integration partner,” a compliance claim that doesn't survive a scope question) surface in the written record where they can't be re-spun in a follow-up call. The same record holds the vendor accountable when post-signature reality starts diverging from the pre-signature pitch, which is the single most common procurement complaint at year-one renewal.
Three things push this template beyond what generic enterprise procurement frameworks already cover. MCP governance, the protocol stack your AI agents will use to talk to tools, where most AI gateway products are still bolting on access control they didn't design for. Agentic AI controls, the trace correlation, cost attribution, and isolation boundaries that turn a multi-step agent task into a debuggable, billable, governable unit instead of a fog of disconnected LLM calls. AI-specific compliance, including audit log field parity between LLM and tool invocations, structured data-residency answers that account for model-provider routing across regions, and the BAA architectural controls that make HIPAA enforcement real rather than paperwork.
Use this as a starting point. Adjust the weights to your environment. Send the same document to every vendor on your shortlist. TrueFoundry's solutions team is set up to answer all 50 questions in writing with evidence as part of the formal enterprise evaluation.
Now to the questions themselves.

Figure 1. Split-plane reference architecture: control plane and compute plane separated by a metadata-only boundary, with one IdP feeding identity into both.
The order of operations matters more than the questions themselves. Most failed evaluations skip step one: getting written answers to the full template before any vendor is allowed to demo. Demos are for verification of written claims, not for discovery. If a vendor's first communication of a feature comes from a slide, you've handed them control of the evaluation narrative.
Send the template to every vendor on your shortlist simultaneously, with a written response deadline two weeks out. Use the responses to score against a weighted rubric. Only after scoring do you book demos, and in those demos your platform team's job is to verify that what's in writing matches what's running. Treat any claim that surfaces in the demo but wasn't in the written response as a discovery to investigate, not a feature to score positively.
A few specifics on running this well:
If you've ever sat through a security review where the vendor's compliance scope only covered the SaaS option you weren't planning to use, you know the cost of skipping the rubric step. A scored RFP forces that detail out before the contract.
Security and compliance is where most AI platform evaluations fall apart in the second meeting. Not because vendors lack certifications. Most have SOC 2 Type II somewhere. The failure mode is alignment: the certification scope, the architectural controls implementing it, and the deployment mode you're actually buying don't match. A SOC 2 covering the vendor's marketing portal does nothing for an AI gateway processing PHI on-prem. A BAA that exists in template form but doesn't describe how PHI is isolated in the data plane is paperwork, not a control. The questions below force the alignment between certification scope and architectural reality that prevents “we're certified” answers from carrying weight they shouldn't.
The other failure mode worth naming early: vendors who answer security questions in the abstract because their concrete architecture is split between two products with different control postures. Their on-prem version is feature-thin and not separately certified. Their SaaS version has the certifications but doesn't fit your environment. Spot this by asking the same question twice with the deployment mode specified each time. If the answers differ, you're looking at two products marketed as one.
Score this section ruthlessly.
A split-plane deployment where the data plane (the proxy that handles prompts, model responses, embeddings, MCP tool invocations) runs entirely in the customer's VPC and never opens an outbound connection to vendor infrastructure for request payloads. The control plane (configuration, RBAC settings, dashboards) may run in vendor infrastructure or customer infrastructure depending on the deployment mode, but exchanges only metadata. Audit logs, prompt-response data, and embeddings land in customer-controlled blob storage (S3, GCS, Azure Blob), not vendor-managed databases. If the vendor's “VPC deployment” still ships prompts to a vendor-managed log aggregator, that's a SaaS deployment in a different wrapper.
Check the System Description section for explicit naming of the deployment modes covered. Look for language like “the multi-tenant SaaS environment hosted in [cloud]” versus “the customer-deployed gateway and control plane components.” If the description names only one, the certification covers only one. Check the Trust Services Criteria covered. Security is the baseline, but Availability, Confidentiality, and Processing Integrity matter for AI workloads handling regulated data. A SOC 2 covering only Security is half the story.
The platform pulls model provider keys from the customer's Vault or Secrets Manager at gateway startup or on-demand using a customer-managed IAM role, with key references (not key values) stored in platform configuration. Rotation is a Vault operation: rewrite the key in Vault, the gateway picks up the new value on next read or on a configurable refresh interval. The platform never persists provider keys at rest. If the vendor's answer is “you upload keys into our admin UI and we store them encrypted,” that's a different (and weaker) security model. The keys are now in vendor infrastructure even in a “VPC” deployment.
{
"event_type": "llm_inference",
"timestamp": "2026-04-28T14:22:31.482Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"model": {
"provider": "anthropic",
"id": "claude-sonnet-4-6",
"version": "20260217"
},
"tokens": {
"input": 1842,
"output": 619,
"cached": 1200
},
"latency_ms": {
"ttft": 312,
"total": 2180
},
"cost_usd": 0.01443,
"policy": {
"guardrails_evaluated": [
"pii",
"content_filter"
],
"decision": "allow"
},
"status": "success"
}The MCP tool invocation log should have field parity for the shared dimensions (timestamp, request_id, trace_id, user, application, latency_ms, status, policy decision) plus the tool-specific fields:
{
"event_type": "mcp_tool_invocation",
"timestamp": "2026-04-28T14:22:32.014Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"mcp_server": {
"id": "github-prod",
"version": "1.4.2"
},
"tool": {
"name": "github.create_issue",
"schema_version": "v2"
},
"parameters_hash": "sha256:7c8b...a31e",
"response_size_bytes": 412,
"latency_ms": 528,
"policy": {
"rules_evaluated": [
"repo_allowlist",
"rate_limit"
],
"decision": "allow"
},
"status": "success"
}Notice the same trace_id on both: the LLM call and the MCP invocation correlate to one user request, which is the answer to Section 4 question 8 made concrete. Hash the parameters rather than logging them raw. Full parameter logging is a data-leakage risk in regulated environments. If the vendor's sample MCP log is missing policy.decision, trace_id, or user attribution, MCP governance is post-hoc reporting, not enforcement.

Figure 2. Audit log data flow: field parity between LLM inference events and MCP tool invocation events, both correlated by one trace_id.
“Encrypted at rest” is universal. Whose key is doing the encrypting is the actual control. In a self-hosted deployment, customer-controlled keys are achievable because the data stores are in the customer's account; in a SaaS deployment, customer-controlled keys are a vendor-side capability that has to be designed in. Ask the question with the deployment mode specified.
For self-hosted deployments, “patch availability” means a tagged release the customer's platform team can deploy. “Customer-applied window” is the SLA the customer signs up for internally. If the vendor proposes a 30-day customer window for critical CVEs, that's a long time to be exposed; push back.
Most enterprise procurement falls apart in deployment. The platform looks great in the SaaS demo, then the security review surfaces three things that block it: outbound connectivity to vendor infrastructure for telemetry, a configuration database hosted in vendor cloud, and a control plane that's tightly coupled to a specific cloud region. By the time those constraints are visible you've already negotiated pricing on the wrong product, and the path forward is either renegotiating from a position of sunk cost or accepting a deployment that creates compliance debt.
This section surfaces deployment constraints upfront. The vendors who can answer it cleanly are the ones who've already deployed in environments like yours. The vendors who need a discovery call to answer Section 2 haven't, and you'll be doing the integration engineering on the discovery call you're paying them for.
Watch the answers carefully.
┌──────────────────────────────────────────────────────┐
│ Customer VPC (one region, two AZs for HA) │
│ │
│ [ALB / NLB] │
│ │ │
│ ├──> Gateway pods (3+ replicas, HPA enabled) │
│ │ ↕ reads keys from │
│ │ [Secrets Manager / Vault] │
│ │ ↕ writes audit + metrics to │
│ │ [S3 / GCS / Azure Blob] │
│ │ ↕ reads config from │
│ │ [Postgres (HA, multi-AZ)] │
│ │ │
│ └──> egress to: model provider APIs, │
│ MCP servers (in-VPC or │
│ allowlisted external) │
│ │
│ [Control plane endpoint] ──> metadata only, │
│ (vendor or self-hosted) no payload data │
└──────────────────────────────────────────────────────────┘
Order-of-magnitude sizing for ~500 RPS sustained: 3 to 4 gateway replicas at 2 vCPU / 4 GB RAM each, Postgres at 4 vCPU / 16 GB RAM with 100 GB SSD, blob storage scaled with retention (a 90-day retention at 10 KB/log entry and 500 RPS is roughly 1.2 TB). The vendor should produce numbers like these in writing before signing, not “depends on workload.”

Figure 3. One control plane managing compute planes across AWS, Azure, GCP, and on-prem Kubernetes simultaneously, each with its own data residency boundary.
Anything worse than this for a multi-region production setup should come with a written explanation. “We don't support multi-region” is acceptable from a small vendor; “we support it but won't commit to RTO” is not.
Every AI gateway product page reads the same: unified API, intelligent routing, cost controls, observability. The specifics behind those words are what separates a gateway you can run in production from a thin proxy with a marketing site. “Intelligent routing” can mean anything from a static round-robin between two models to a real cascading policy with cost ceilings, capability matching, and fallback chains. “Cost controls” can mean a dashboard that shows you yesterday's bill, or it can mean hard token budgets that actually return a 429 to the application when a team hits its limit.
The questions in this section force the specifics out. Reject responses that restate the marketing copy back to you. The vendor who says “we support intelligent routing” without describing the rule language, the cascade behavior, the failure handling, and the budget integration doesn't have routing. They have a config flag.
Make them prove the architecture exists.
route: chat-support
match:
application: app_chat_support
team: applied-ml
strategy: cascade
cascade:
- model: claude-sonnet-4-6
provider: anthropic
conditions: { max_input_tokens: 1000000 }
- model: gpt-5.5
provider: openai
conditions: { fallback_on: ["rate_limit", "5xx"] }
- model: claude-haiku-4-5
provider: anthropic
conditions: { fallback_on: ["all_above_failed"] }
guardrails: [pii, content_filter]
budget_ref: budget_applied_ml_q2
The application sends a standard OpenAI-compatible request. The gateway picks the provider based on the rule, falls down the cascade on failure, attaches the budget reference for cost attribution, and applies guardrails inline. No application code changes when the route is reconfigured. If the vendor's “intelligent routing” requires application-level changes for every variant, that's not gateway-level routing. It's a wrapper.
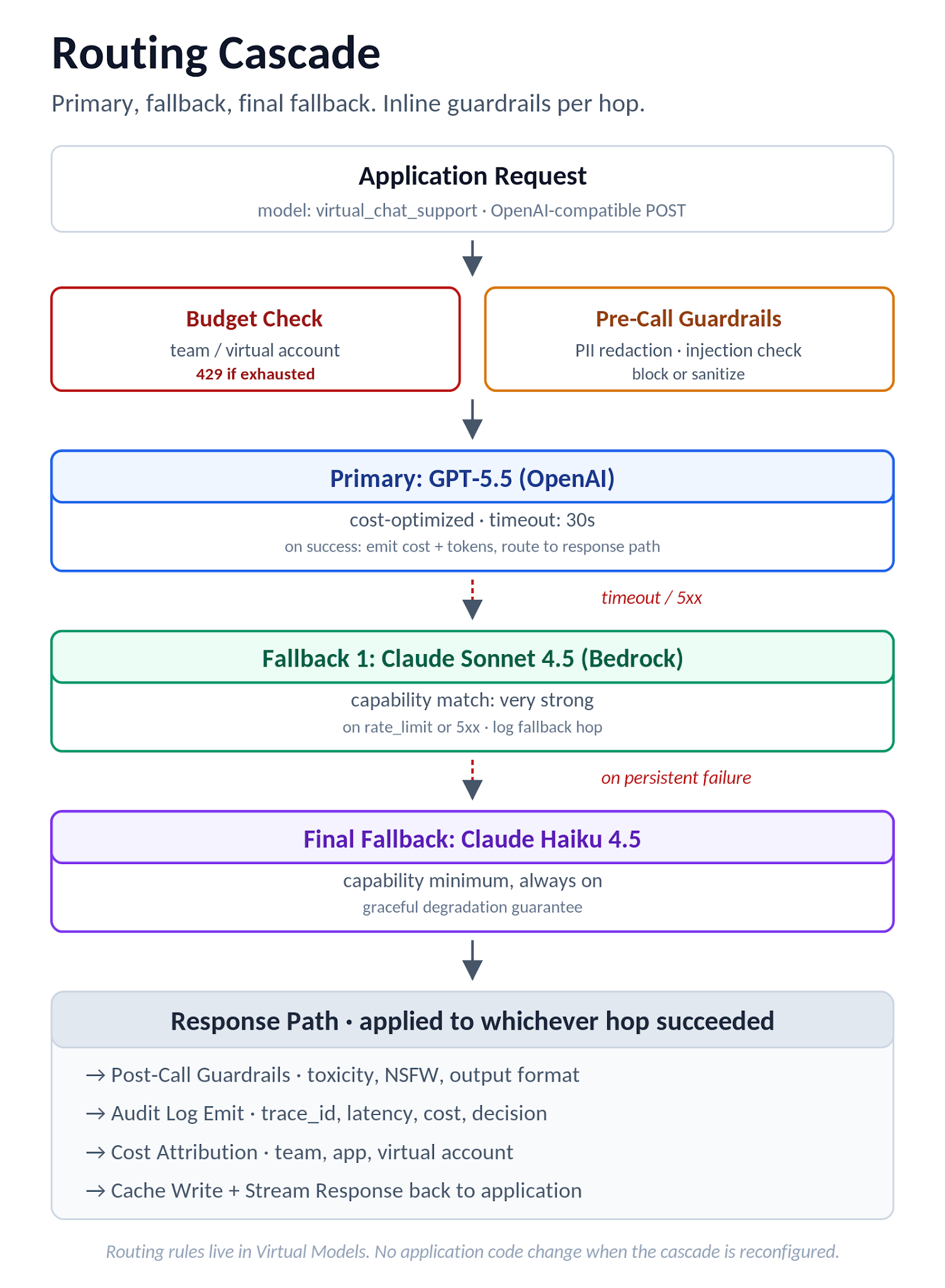
Figure 4. Routing cascade flow: budget check, pre-call guardrails, primary model attempt, fallback chain, and a unified response path with audit, cost, and cache.
This section is where most AI gateway products will struggle, because most of them were designed for the LLM-call era and predate the moment MCP started showing up in real enterprise environments. MCP isn't “more observability for tool calls.” It's a separate governance plane: a registry of approved servers, an enforcement point for which tools each role can invoke, audit logs that match the LLM call logs in field coverage, and a policy engine that runs at invocation time rather than as a post-hoc report. Vendors who don't have this plane will try to answer Section 4 questions with descriptions of LLM observability. Watch for the substitution. The more direct the answer, the more real the capability.
The pattern to expect: a strong AI gateway vendor will describe the MCP gateway as a separate product surface with its own registry, its own RBAC mapping, its own audit log schema, and its own policy language. A weaker vendor will describe it as “extended observability” over their existing LLM observability stack, which is the giveaway that the governance is sparse. Score Section 4 specifically; do not roll it into Section 3.
Read each answer for direct enforcement language.
policy: github-write-restriction
applies_to:
mcp_server: github-prod
tool_pattern: "github.*"
rules:
- match:
tool: github.delete_repo
action: deny
reason: "Destructive operations require change-management ticket"
- match:
tool: github.create_pr
user.team: ["junior-engineers"]
parameters.target_branch: "main"
action: deny
reason: "Direct-to-main PRs require senior-engineer approval"
- match: {tool: "github.*"}
action: allow
log_level: full
يجب أن تنتشر تحديثات هذه القاعدة إلى البوابة في غضون ثوانٍ (دفع التكوين، وليس إعادة النشر). إذا كان رد البائع هو أن "السياسات يتم تقييمها بواسطة خادم MCP نفسه"، فهذه ليست سياسة تفرضها البوابة. إنها سياسة يفرضها الخادم، وستحتاج إلى الحفاظ على تكافؤ السياسات عبر كل خادم MCP في الكتالوج. مشكلة مختلفة.
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
└─ trace-id (32 hex) └─ span-id (16 hex)
تحافظ البوابة على معرف التتبع (trace-id) عبر كل استدعاء لاحق (مزود LLM، خادم MCP، قفزة بوابة ثانوية) عن طريق حقنه في الرؤوس الصادرة، وتصدر كل استدعاء كامتداد (span) تحت نفس معرف التتبع. في Datadog أو Grafana Tempo أو Jaeger، تكون النتيجة شلالًا واحدًا يوضح: طلب المستخدم ← استدعاء LLM (claude-sonnet-4-6، 2.1 ثانية) ← استدعاء أداة (github.create_issue، 528 مللي ثانية) ← استدعاء LLM (منسق الإخراج، 380 مللي ثانية) ← استجابة. بدون ذلك، يظهر نفس التدفق كأربعة إدخالات غير مرتبطة ويصبح تحليل السبب الجذري مجرد تخمين.

الشكل 5. هندسة بوابة MCP: نقطة نهاية واحدة لأدوات المطورين والوكلاء، مع طبقات المصادقة، والتسجيل، والسياسة، والتسجيل بين العملاء وخوادم MCP.
يظهر الفرق بين منصة ذكاء اصطناعي تراقب جيدًا ومنصة تراقب بعمق في الأسئلة التي يطرحها فريقك المالي في نهاية الشهر. تخبرك المراقبة أن الفاتورة ارتفعت بنسبة 40 بالمائة. تخبرك قابلية المراقبة أن روبوت الدردشة الخاص بفريق التسويق بدأ في التكرار على حالة حدية لنافذة السياق قبل ثلاثة أسابيع، وأن 70 بالمائة من الزيادة تأتي من تطبيق واحد، وأن الطلبات الجامحة لها توقيع محدد يمكنك توجيهه إلى نموذج أرخص. الإجابة الأولى تجعل فريق المالية غاضبًا. الإجابة الثانية تجعل فريق المالية حليفًا.
يظهر نفس التمييز في تصحيح أخطاء الوكيل. تخبرك المراقبة أن مهمة وكيل قد فشلت. تخبرك قابلية المراقبة أي استدعاء LLM أعاد استجابة غير صحيحة، وأي استدعاء أداة لاحق انتهت مهلته نتيجة لذلك، وأي طلب مستخدم أدى إليه الفشل. بدون التتبع المترابط عبر مستويات LLM و MCP (القسم 4 السؤال 8)، يصبح كل فشل وكيل تمرينًا جنائيًا. الأسئلة أدناه تجبر البائع على وصف ما يتم التقاطه فعليًا لكل استدعاء، وكيف يمكن الاستعلام عنه، وكيف تخرج البيانات من المنصة عندما يحتاجها نظامك المالي.
التفاصيل مهمة هنا.
agent_task: trace_id 4bf92f35...
user: ana@company.com (team: applied-ml)
initiating_request: app_chat_support, 2026-04-28 14:22:31
duration: 4.8s
components:
- llm: claude-sonnet-4-6 | tokens 1842 in / 619 out | $0.0144
- tool: github.create_issue | latency 528ms | n/a
- llm: claude-haiku-4-5 | tokens 412 in / 87 out | $0.0011
total_cost_usd: $0.0155
total_tokens: 2960
هذا ما يجعل "إسناد تكلفة الوكيل" إشارة ذات مستوى مالي بدلاً من مجرد فضول تقني.

الشكل 6. عرض شلال التتبع لمهمة وكيل واحدة: استدعاء LLM، استدعاء أداة MCP، واستدعاء LLM ثانٍ، وكلها تحت معرف تتبع واحد (trace_id) مع تجميع التكلفة عبر الامتدادات (spans).
نادرًا ما تكون تكلفة فجوة التكامل مرئية عند الشراء. تظهر بعد ستة أشهر، عندما يستغرق إلغاء وصول موظف تم إنهاء خدمته 48 ساعة لأن SCIM ليس حقيقيًا، عندما تتلقى مشكلة P1 في الساعة 2 صباحًا ردًا تلقائيًا "سنرد خلال ساعات العمل" لأن اتفاقية مستوى الخدمة طموحة، عندما يؤدي تغيير اسم مجموعة Okta إلى تعطيل تعيينات الأدوار لأن تكامل SSO للمنصة لم يتم اختباره أبدًا مع أحداث دورة حياة المجموعة. كل من هذه التكاليف هي تكلفة هندسية محدودة، لكنها تتراكم لتشكل الضريبة التشغيلية التي تجعل فرق المنصة تهاجر بهدوء من المنتجات القادرة بخلاف ذلك عند تجديد السنة الثالثة.
يكشف القسم 6 عن الحقائق التشغيلية. نمطان تشخيصيان: أي إجابة "نعم" على سؤال دعم البروتوكول تستحق متابعة حول العملاء الذين يستخدمون هذا البروتوكول في الإنتاج اليوم مقابل العملاء الذين سيكونون أول من يجربه. وأي التزام باتفاقية مستوى الخدمة (SLA) بدون تعويضات صريحة يجب أن يُعامل كهدف تسويقي. اتفاقيات مستوى الخدمة التعاقدية تأتي مع تعويضات لأن البائعين يسعرون مخاطر عدم الالتزام بها؛ أما اتفاقيات مستوى الخدمة الطموحة فتكتبها أقسام التسويق ولا تتضمن تعويضات.
احصل على التعويضات كتابةً.
إذا كانت المنصة لا تستطيع استهلاك سوى تنسيق مطالبة ثابت واحد، يصبح التكامل مع أي شيء آخر غير Okta/Azure AD مؤلمًا. المرونة المذكورة أعلاه هي تكلفة تهيئة لمرة واحدة؛ بدونها، يصبح كل إعداد لموفر هوية (IdP) بمثابة مشاركة مخصصة.
POST /scim/v2/Users
Authorization: Bearer <scim-token>
Content-Type: application/scim+json
{
"schemas": ["urn:ietf:params:scim:schemas:core:2.0:User"],
"userName": "ana@company.com",
"name": {"givenName": "Ana", "familyName": "Ruiz"},
"emails": [{"value": "ana@company.com", "primary": true}],
"groups": [{"value": "applied-ml"}, {"value": "ai-platform-developer"}],
"active": true
}عندما يتم إلغاء توفير المستخدم في موفر الهوية (IdP)، تتلقى نفس نقطة النهاية طلب PATCH يغير حالة "نشط" إلى "خطأ"، ويجب على المنصة إلغاء وصول المستخدم على الفور بدلاً من الانتظار حتى محاولة تسجيل الدخول التالية. اختبر هذا في إثبات المفهوم: قم بإلغاء توفير مستخدم اختباري في موفر الهوية، ثم حاول استخدام رمز منصة لا يزال صالحًا، وتأكد من أن دورة حياة إلغاء التوفير تعمل من البداية إلى النهاية. إذا كانت المنصة لا تحترم إلغاء التوفير إلا عند تسجيل دخول المستخدم التالي، فهذه فجوة امتثال تستحق الإشارة إليها كتابةً.
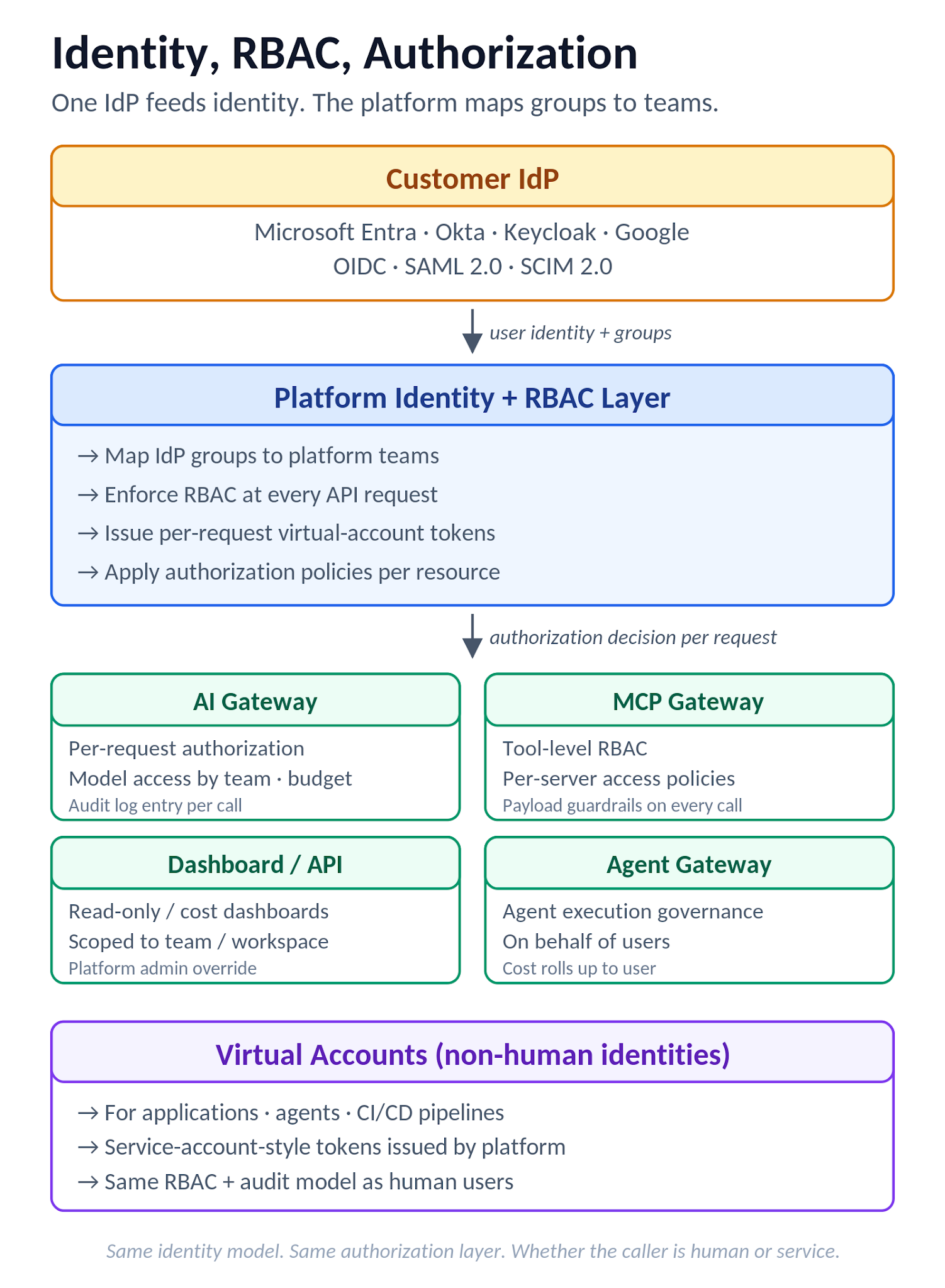
الشكل 7. تدفق الهوية والتحكم في الوصول المستند إلى الدور (RBAC): يغذي موفر الهوية (IdP) الهوية، وتقوم المنصة بربط المجموعات بالفرق والحسابات الافتراضية، مع تطبيق ذلك عند بوابة الذكاء الاصطناعي (AI Gateway)، وبوابة MCP، ولوحة التحكم، وبوابة الوكيل (Agent Gateway).
احذر من تعريف "وقت الاستجابة" بأنه "رسالة بريد إلكتروني تلقائية تفيد بأننا تلقينا تذكرتك." هذا ليس استجابة. الاستجابة الحقيقية هي مهندس يتعامل مع المشكلة. وبند التعويض هو الاختبار: اتفاقيات مستوى الخدمة التعاقدية تأتي مع تعويضات، أما اتفاقيات مستوى الخدمة التسويقية فلا.
يتعامل فريق حلول TrueFoundry مع طلب تقديم العروض هذا كتقييم رسمي، وليس مجرد وثيقة مبيعات. يحصل كل سؤال على رد مكتوب مع أدلة: تقارير SOC 2 من النوع الثاني، وثائق اتفاقية شراكة الأعمال (BAA) لعمليات النشر في مجال الرعاية الصحية، ملخصات اختبار الاختراق، معماريات مرجعية، عينات من سجلات التدقيق، ومراجع العملاء. الناتج هو وثيقة تستخدمها فرق الأمان والمشتريات والمنصة لاتخاذ قرار دون الحاجة إلى مكالمة استكشافية لسد الفجوات.
تتوافق البنية المعمارية التي تستند إليها الإجابات مباشرة مع هيكل أقسام هذا القالب، وهذا هو السبب في أن معظم الأسئلة تُحل بوضوح. لنستعرضها:
نموذج النشر هو "المستوى المنفصل" (split-plane). مستوى التحكم هو العقل المدبر للتنسيق، يستضيف التكوين، والتحكم في الوصول المستند إلى الأدوار (RBAC)، ولوحات المعلومات. تتصل مستويات الحوسبة مرة أخرى عبر وكيل وتستضيف أعباء العمل الفعلية، بما في ذلك بوابة الذكاء الاصطناعي (AI Gateway)، وبوابة MCP، وأي تطبيقات منشورة أو نماذج مستضافة ذاتيًا. يمكن أن تعمل مستويات الحوسبة في حسابات السحابة الخاصة بالعميل (AWS, GCP, Azure) أو على Kubernetes المحلي، وتتصل مستويات حوسبة متعددة بمستوى تحكم واحد لتمكين عمليات متعددة البيئات تحت سطح تحكم واحد. يمكن استضافة بوابة الذكاء الاصطناعي ذاتيًا داخل البنية التحتية للعميل (خيارات النشر موثقة بشكل منفصل) للتحكم في إقامة البيانات وسيادتها. يتم تخزين سجلات التدقيق وبيانات التتبع باستخدام تسجيل طلبات البوابة ومشاريع التتبع، مع تحكم RBAC في الوصول إلى التتبعات والسجلات. إن بنية المستوى المنفصل هي ما يجعل نفس وضع إقامة البيانات متاحًا عبر عمليات النشر كخدمة (SaaS)، والسحابة الواحدة، والسحابة المتعددة، والمستضافة ذاتيًا، بدلاً من التعامل مع كل منها كمنتج منفصل بوضعيات تحكم منفصلة.
سيادة البيانات هي البنية المعمارية، وليست مجرد شعار تسويقي.
تستخدم المصادقة تسجيل الدخول الموحد للشركات (SSO) عبر OIDC أو SAML 2.0 مع التحقق الاختياري من رمز IdP مباشرة عند بوابة الذكاء الاصطناعي للتحكم في الوصول إلى واجهة برمجة التطبيقات. يتم دعم موفري الهوية الشائعين (Microsoft Entra ID, Okta, Keycloak, Google)، مع مطابقة مطالبات الهوية وعضويات المجموعات من موفر الهوية إلى فرق TrueFoundry لدفع التحكم في الوصول المستند إلى الأدوار (RBAC) على نطاق واسع. يتم دعم توفير SCIM على جميع تكوينات SSO — سواء OIDC أو SAML — بحيث ينتشر إلغاء التوفير في موفر الهوية بدلاً من انتظار تسجيل دخول المستخدم التالي. يعمل RBAC على مستوى المستأجر (أدوار المسؤول/العضو) بالإضافة إلى أدوار مخصصة ذات أذونات محددة النطاق عبر المستخدمين والفرق والمجموعات ومساحات العمل وعمليات النشر وحسابات موفري بوابة الذكاء الاصطناعي وخوادم MCP ومشاريع التتبع. تحصل الهويات غير البشرية (التطبيقات، الوكلاء) على حسابات افتراضية برموز مميزة على غرار حسابات الخدمة، ويدعم التفويض لكل طلب عند حدود بوابة الذكاء الاصطناعي (النماذج، الوكلاء، خوادم وأدوات MCP) أنماط الامتياز الأقل. تتكامل مفاتيح الموفر مع مخازن الأسرار التي يديرها العميل؛ يتم وضع مصادقة البوابة فوق موفر الهوية بدلاً من استبداله، لذلك تظل المصادقة متعددة العوامل (MFA) والوصول المشروط مفروضة بواسطة موفر الهوية الخاص بالعميل.
تقوم بوابة الذكاء الاصطناعي بتوجيه أكثر من 1000 نموذج لغوي كبير (LLM) عبر نقطة نهاية واحدة متوافقة مع OpenAI: OpenAI، Anthropic (مباشرة وعبر AWS Bedrock)، Azure OpenAI، GCP Vertex AI، Groq، Mistral، والنماذج المستضافة ذاتيًا التي يتم تقديمها عبر vLLM، TGI، أو Triton. يتم تكوين التوجيه عبر النماذج الافتراضية (Virtual Models)، التي تعرض واجهة نموذج واحدة وتوازن الحمل أو تتجاوز الأعطال عبر موفري ونماذج متعددة. يضيف TrueFailover توجيهًا مدركًا للانقطاعات والتدهور، مع مرونة مدمجة متعددة المناطق والسحابات. تعيد حدود الرموز والطلبات الصارمة لكل مستخدم أو فريق أو حساب افتراضي رفضًا منظمًا عندما يصل الفريق إلى ميزانيته بدلاً من تنبيه بسيط مع استمرار الطلب. يكون الرجوع إلى الموفر تلقائيًا ويتم تسجيل عقوبة زمن الاستجابة كمقياس منفصل في المكالمة بدلاً من دفنها في إجمالي زمن الاستجابة. يستخدم التخزين المؤقت الدلالي التضمينات وتشابه جيب التمام مع عتبة قابلة للتكوين ومدة البقاء (TTL)؛ تشير الوثائق إلى تحسن في زمن الاستجابة يصل إلى 20 ضعفًا للاستعلامات المتكررة أو المتشابهة. الحواجز (Guardrails) قائمة على القواعد (تستهدف حسب النموذج أو المستخدم أو البيانات الوصفية)، ويمكن لكل منها التحقق (الحظر) أو التعديل (إعادة الكتابة/التنقيح)، ويتم دعم "إحضار حاجزك الخاص" (Bring-Your-Own Guardrail) من خلال خادم حاجز مخصص باستخدام قالب FastAPI.
التوجيه هنا هو المنتج، وليس مجرد علامة تكوين.
مكدس MCP والوكيل هو ما يميزنا. تدير TrueFoundry بوابة MCP وسجل MCP أصليين يقومان بتسجيل واكتشاف وربط خوادم وأدوات MCP بشكل آمن ومركزي من خلال ضوابط الوصول المحكومة وتدفقات المصادقة للشركات. يتم دعم وسائل نقل MCP الحديثة بما في ذلك HTTP القابل للتدفق لاتصالات الوكيل، وتستخدم طبقة البروتوكولة رسائل JSON-RPC القياسية وفقًا لمواصفات MCP. المصادقة متعددة الطبقات: مصادقة البوابة، والتحكم في الوصول إلى خوادم MCP، والمصادقة لكل خادم أو أداة (بما في ذلك الأنماط المستندة إلى OAuth الموثقة لخوادم MCP للشركات). يعني التكوين المركزي أن أدوات المطورين تتحدث إلى نقطة نهاية بوابة واحدة بدلاً من قيام كل مطور بتوصيل اتصالات MCP الخاصة به، وهو نمط "الأدوات الخفية" الذي تم تصميم السجل لمنعه. يوفر Agent Hub فهرسة تنظيمية وتنسيقًا للوكلاء المعقدين والوكلاء الموجودين مسبقًا، وتوفر Agent Gateway طبقة حوكمة الشركات (الوصول الآمن للأدوات، المراقبة، ضوابط التكلفة) لتشغيل هؤلاء الوكلاء في الإنتاج. نفس الهوية التي تحكم الوصول إلى LLM تحكم الوصول إلى الأدوات، لذلك يعيش التفويض لكليهما في تكوين IdP واحد. ونفس سياق التتبع الذي يربط مهمة وكيل LLM متعددة الخطوات يربط استدعاءات MCP تحتها، وهذا ما يجعل تجميع التكلفة لكل مهمة وتصحيح الأخطاء الشامل ممكنًا بدلاً من كونه نظريًا.
تستخدم قابلية المراقبة تسجيل طلبات البوابة مع التتبعات. يتم التقاط عدد الرموز، والتكاليف، وزمن الاستجابة (TTFT والإجمالي)، وقرارات الحواجز، وقرارات السياسات، وتحديد الفريق والتطبيق لكل مكالمة، وتخزينها كتتبعات، ويمكن الوصول إليها من خلال مشاريع التتبع مع التحكم في الوصول المستند إلى الأدوار (RBAC) الخاص بها. تصدير القياس عن بعد يعتمد على المعايير: تصدير بيانات OpenTelemetry بالإضافة إلى تصدير السجلات والتتبعات إلى أنظمة خارجية بما في ذلك Grafana وDatadog وPrometheus، بحيث يتكامل العملاء مع مكدسات المراقبة الحالية بدلاً من تعلم مكدس خاص. لوحات معلومات التكلفة في الوقت الفعلي ويمكن مشاركتها مع قادة الفرق من خلال RBAC للقراءة فقط. نفس مخزن السجلات/التتبعات هو ما ينشئ مجموعة البيانات القابلة للتدقيق لمحاولات حقن الأوامر، وضربات السياسات، وأنماط الإساءة التي يمكن للعملاء استكشافها لضبط الحواجز بمرور الوقت.
مكدس المراقبة الحالي الخاص بك يظل كما هو.
دليل الإنتاجية وراء كل هذا: معالجة 10 مليارات طلب شهريًا عبر قاعدة العملاء، وأكثر من 1000 مجموعة Kubernetes تديرها المنصة، وحمل زائد من جانب البوابة أقل من 10 مللي ثانية p95 (TTFT) وأكثر من 350 طلبًا في الثانية (RPS) مستدامًا على وحدة معالجة مركزية افتراضية واحدة. يشمل العملاء الذين يعملون في الإنتاج Resmed، Siemens Healthineers، Automation Anywhere، Zscaler، و Nvidia. قادت Intel Capital جولة التمويل من الفئة A في فبراير 2025، ليصل إجمالي التمويل إلى حوالي 21 مليون دولار بمشاركة Peak XV Partners (Surge)، و Eniac Ventures، و Jump Capital.
نطاق الإنتاج، وليس نطاقًا تجريبيًا.
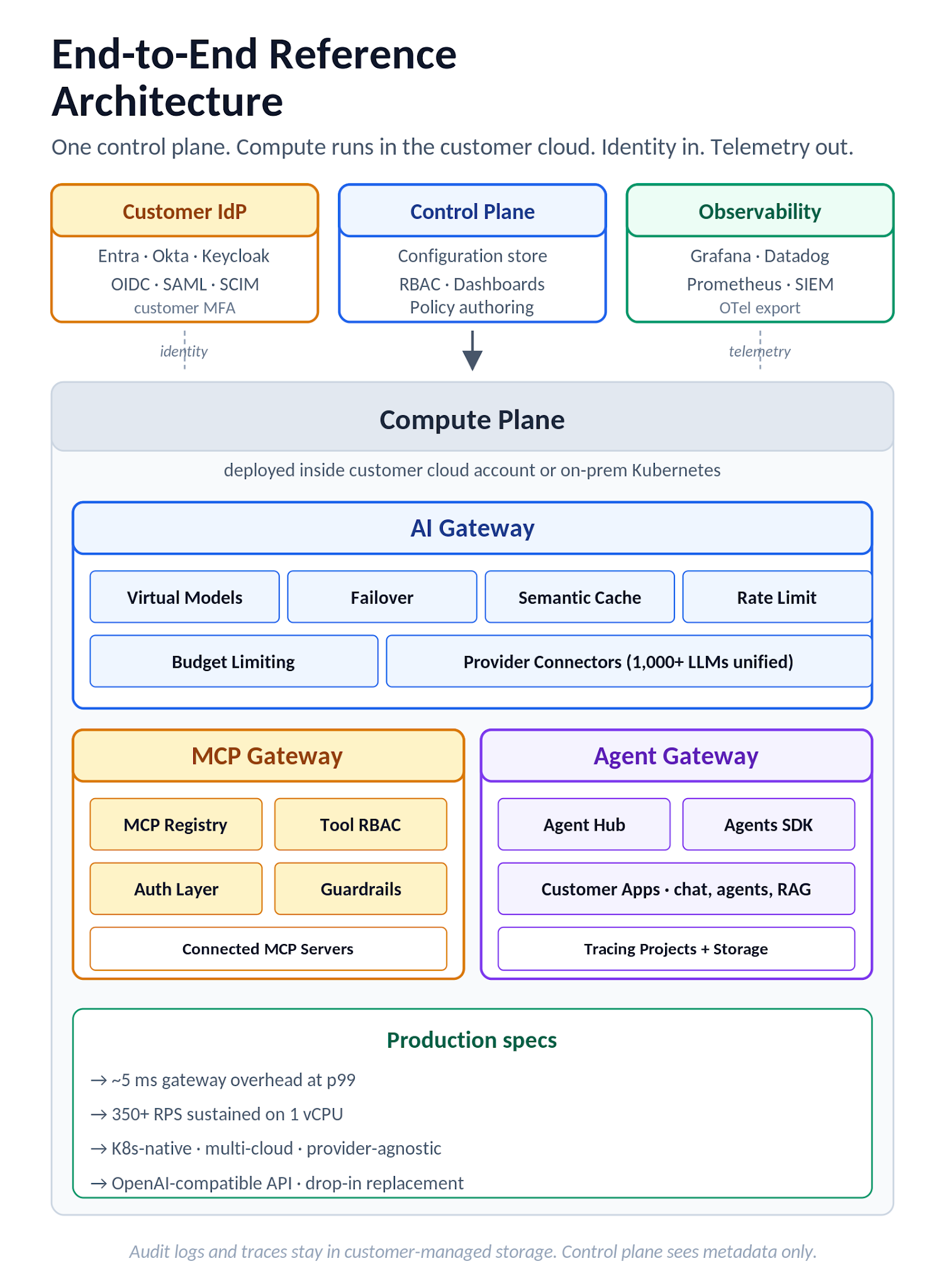
الشكل 8. بنية TrueFoundry المرجعية الشاملة: مستوى التحكم، مستوى الحوسبة (مع بوابة الذكاء الاصطناعي، بوابة MCP، بوابة الوكيل وتطبيقات العملاء)، موفر هوية العميل، وأهداف المراقبة.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
