Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Machine learning (ML) and large language model (LLM) workloads are notoriously expensive to run in the cloud. This is because they require significant amounts of computing power, memory, and storage. However, there are ways to reduce your cloud costs for ML/LLM workloads without sacrificing scalability or reliability.
Key Principles on How to Reduce Costs
Better Visibility for DevOps Engineers and Developers: Getting visibility on cloud costs is difficult, especially when you have multiple components deployed across multiple clouds. TrueFoundry provides visibility into cloud costs at the cluster, workspace, and deployment levels, empowering DevOps teams and developers to identify and optimize cost-saving opportunities throughout the ML/LLM lifecycle.
Ease of Resource Adjustment: TrueFoundry enables DevOps teams and developers to take action on the cost visibility they have gained.
DevOps teams can set resource constraints at the project level, ensuring that each team's workloads have access to the resources they need without exceeding budget.
Developers can also easily adjust resources on the go, based on the insights they get. Additionally, TrueFoundry makes it easy to scale applications and IDEs to zero in non-production environments, eliminating the cost of idle resources and making iteration cycles for cost reductions more efficient.
Infrastructure Optimization for Cost: TrueFoundry's Kubernetes-based architecture and infrastructure optimizations are designed to reduce cloud costs.
Overall, TrueFoundry's cost-saving features provide DevOps teams and developers with the visibility, control, and optimization capabilities they need to reduce cloud costs throughout the ML/LLM lifecycle.
AMI to Docker Transition: Our platform has eased a lot of companies to migrate from AMI to Docker, where companies have already experienced cost savings of 30 to 40 percent.
TrueFoundry: Your Cost-First Platform
Truefoundry is a "cost-first" platform, built around Kubernetes, designed with an architecture that prioritizes efficiency, scalability and cost reductions.
Let's explore how TrueFoundry's unique architecture empowers you to save on costs while optimizing for reliability and scalability. Here's the platform's hierarchical structure:
Clusters: Connect all your clusters, whether it's AWS EKS, Azure AKS, GCP GKE, or an on-prem cluster, to the platform. This allows you to seamlessly integrate all your clusters at one place. These clusters are the foundation for deploying a wide range of services, models, and jobs.
Workspaces: Within clusters, we introduce workspaces, providing a streamlined approach to add access control and isolation to ensure that each project or environment has its own dedicated resources and is protected from unauthorized access. Think of them as groups of deployments.
Deployments: Within these workspaces, we have deployments and we support you to deploy different kinds of things. With TrueFoundry, you can effortlessly cover every aspect of your ML development lifecycle.
Interactive Development Environments: Deploy Jupyter Notebook and VS Code for collaborative experimentation.
Training and Fine-tuning Jobs: Efficiently train ML models or fine-tune LLM models by deploying as a job.
Pre-trained LLMs: Swiftly deploy pre-trained Large Language Models for specific use cases using our Model Catalogue.
Services and Apps: Deploy a variety of services and applications, including models, web apps etc.
Application Catalog: Deploy popular software like Label Studio, Redis, Qdrant etc. with ease.
Cost savings at Cluster Level
Kuberenetes-based infrastructure
Kubernetes contributes to cost reduction by employing bin packing to optimize resource utilization, efficiently placing containers and ultimately lowering infrastructure costs.
To learn more about how TrueFoundry leverages Kuberenetes read here.
💡
EC2 to Kubernetes Migration: Many companies have successfully moved from EC2 machines to Kubernetes after onboarding into our platform, leading to cost savings due to improved resource allocation
Multi-cloud support
TrueFoundry's multi-cloud architecture makes it easy to connect to different cloud providers.
Flexibility to Switch Between Clouds: By having the ability switch between different cloud providers easily, you can take advantage of the best prices and features from different providers.
Distribute Workloads Across Clouds and Regions: By spreading out your workloads across multiple cloud providers and regions. This can help to reduce costs by distributing your workloads across different pricing tiers and regions. It also helps to improve performance and reliability by reducing your reliance on a single cloud provider.
High Instance Quota Availability: By using multiple cloud providers, you can get access to more resources. This can help you to save money and avoid any limitations on the resources you need.
Scaling LLMs across multiple clouds and regions
💡
A mid-level conversational AI chatbot provider with high user traffic (20+ RPS and 2 million plus requests per day) runs entirely on distributed spot GPU instances over five clusters across different clouds and regions using our asynchronous service. This reduces their infrastructure costs by 60% while improving reliability and throughput.
Enhanced Visibility
For every cluster, you can view the number of nodes running in the Cluster. You can also get insights on node-specific details like
Savings Analysis: See the percentage of cost being saved for each node
Resource Allocation Insights: See current usage, resource request and limit for making informed decision.
Capacity Type Insights: See which type of nodes are running in your cluster, whether they are spot or on-demand nodes.
Cost Savings at Workspace Level
Resource limits
TrueFoundry allows you to create multiple workspaces within a cluster. This segmentation helps you organize your deployments for different teams or environments.
Resource Constraints: Customize resource constraints for each workspace, including CPU, memory, storage, and even instance families. This allows you to allocate the resources to meet the specific requirements of your project or environment.
Supported instance families: Tailor your workspace to specific performance requirements and budget by selecting the instance families it will support.
For example, if a project doesn't require high-performance computing, you can disable larger instances in its workspace. This will help to prevent developers from overprovisioning resources, which can save money.
Supported node pools: Nodepools are groups of nodes that provide the computational resources for your workloads. You can choose the node pools that best suit your workloads and budget.
For example, you can create a node pool with A100 GPUs. Then, you can only enable that specific node pool for project workspaces that require access to that kind of GPU.
Track Workspace level cost
We also give you visibility to track your workspace level cost based on past usage. This will allow you to identify which projects or environments are using the most resources and where you can make savings.
Cost Savings at Deployment Level
We offer advanced features at the application level to help you achieve significant cost savings:
Spot Instances with Fallback to On-Demand: Usually applications struggle to balance cost and reliability. TrueFoundry lets you select capacity type for your nodes, including spot instances with fallback to on-demand resources. This ensures that your applications remain available even if a spot instance is evicted, offering the optimal balance between cost and availability.
Pausing Services: Pause services when they're not in use to save costs. Easily pause or resume services from the deployments page.
Resource Optimization: Ensure that your resources are optimally allocated and your services are running at the right capacity.
Resource Monitoring: Track your service's resource utilization in real-time, including CPU and GPU allocation. Get alerts on over-provisioning, under-provisioning, and receive resource recommendations.
Dynamic Resource Adjustment: Adjust resource levels on the fly to scale down to a lower CPU resource and redeploy your service accordingly.
Time-Based Autoscaling: Schedule resource adjustments based on time to reduce costs in non-production environments during periods of low usage.
💡
Many of our clients save over 60% on their development environment cloud costs by scheduling shutdowns during non-working hours, reducing compute usage by 128 hours per week.
Cost Savings at Code Editors Level
We offer certain features for Code Editors, you can achieve significant cost savings at the Notebook and VSCode level:
Shared Volumes: Use volumes based on requirements to share large data among Notebooks and VSCode Instances and facilitate collaboration. Shared volumes reduce redundancy and enhance efficiency, especially when multiple users need access to substantial data across Notebooks and VSCode Instances.
Adaptive Resource Usage: Easily switch between CPU and GPU on the same machine to optimize resource allocation. You don't have to maintain a GPU resource constantly, only when needed.
💡
A generative AI company operating in the video generation segment, which runs hundreds of Jupyter Notebooks on spot instances for non-production workloads, saved around 50-60% in cloud costs by switching on GPUs only when needed.
Manual Pausing: Easily Pause Notebooks/VSCode instances when not in use. The code and data is persisted, ensuring a seamless restart when needed.
Automatic Pausing: Configure your Notebooks/VSCode instances to pause automatically after a certain period of inactivity to save valuable resources.
💡
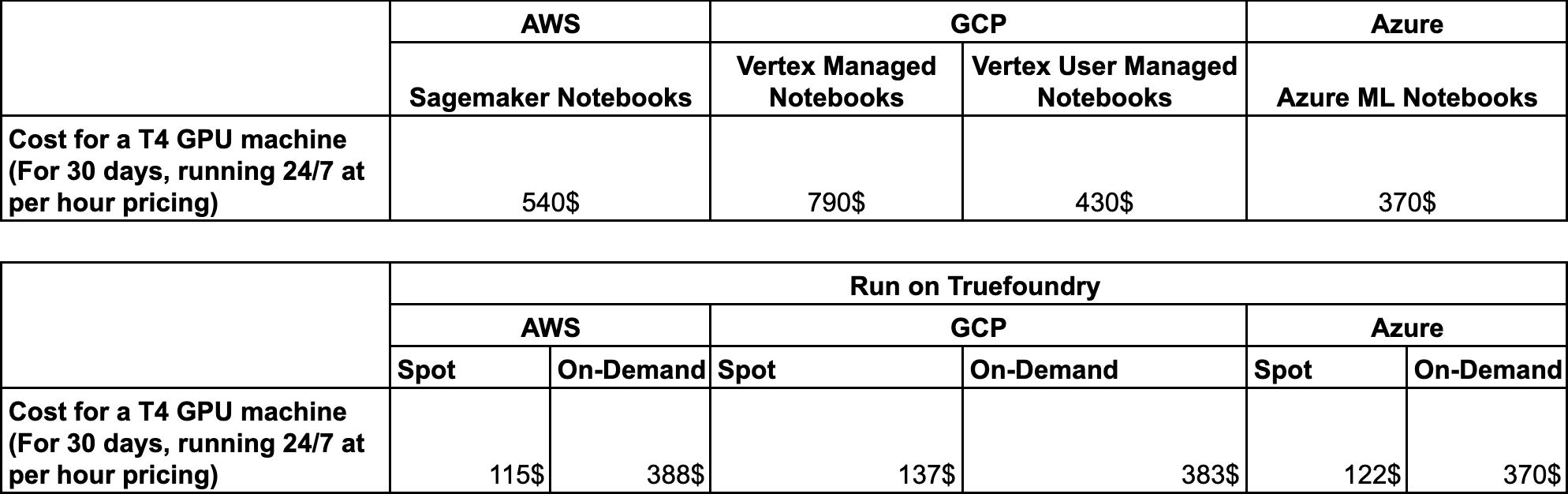
Cost Benchmarking We have conducted benchmarking across AWS, GCP, and Azure to compare the cost savings of running Notebooks and VSCode on-demand or using the corresponding cloud.
Cost Savings in Deploying and Fine-Tuning Large Language Models (LLMs):
Our Model Catalogue provides a convenient one-stop shop for deploying and fine-tuning well-known pre-trained LLMs. We have taken these steps to ensure that deployment and fine-tuning of these LLMs are as cost-efficient as possible:
Optimized Model Serving Configuration: Based on benchmarking for various model servers and resource allocations, we provide you with pre-filled configurations that give the best latency and throughput. This simplifies the process of deploying LLMs and helps you to make your deployments resource-efficient and cost-effective.
Efficient Fine-Tuning Configuration: We provide efficient methods for fine-tuning, such as LoRA and Q-LoRA, which help to reduce resource usage and allow you to achieve your goals at lower costs.
Scalable Deployments with Async Support: Deploy LLMs at scale with async support to utilize your GPU quotas in all three clouds and reliably get the GPUs you need for fine-tuning and deployment. This added reliability allows you to use spot instances, saving money.
Benchmarking We've conducted cost benchmarking to compare the expenses of deploying LLMs on AWS EKS versus SageMaker. You can read more in the blog below.
Several Fortune 100 companies and mid-market businesses have saved significantly by using our platform. Some have even replaced their internal SageMaker or cloud platforms with our system, saving 30-40%.
We have also Benchmarked the performance of a lot of common open-source LLMs in these series of articles from latency, cost, and requests per second perspective. You can check them out at TrueFoundry Blogs
You can also view this video to get a live demo of all the features we covered in this blog:
TrueFoundry is a ML Deployment PaaS over Kubernetes to speed up developer workflows while allowing them full flexibility in testing and deploying models while ensuring full security and control for the Infra team. Through our platform, we enable Machine learning Teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds - allowing them to save cost and release Models to production faster, enabling real business value realisation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.






















































.webp)


.webp)
.webp)
.webp)
.png)






.webp)
.webp)