Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
9.9
Gemini 3 vs Kimi-K2 Thinking vs Grok-4.1 vs GPT-5.1: Who Actually Wins Humanity’s Last Exam?
Published: March 30, 2026
Built for Speed: ~10ms Latency, Even Under Load
Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed
When Google says “Plan anything” with Gemini 3, Moonshot claims Kimi-K2 Thinking is the new reasoning SOTA, xAI calls Grok-4 “the most intelligent model in the world”, and OpenAI keeps pushing GPT-5.1 forward, it’s hard to know what’s real and what’s just vibes.
Instead of another wall of benchmark charts, here’s a narrower question:
What happens if you put Gemini 3, Kimi-K2 Thinking, Grok-4.1 and GPT-5.1 through the same set of Humanity’s Last Exam–style problems — and actually watch how they think?
In this post:
Why Humanity’s Last Exam (HLE) has become the “final boss” of academic benchmarks.
A quick tour of Gemini 3, Kimi-K2 Thinking, Grok-4.1 and GPT-5.1 as “thinking” models.
Five concrete HLE-style case studies across math, multimodal physics, long-context science, game theory and planning.
How to run the same experiments yourself via the TrueFoundry AI Gateway.
1. Humanity’s Last Exam in 2 minutes
Benchmarks like MMLU are basically “done” at the frontier. Many top models are above 90% there, so another model being +1 or −1% doesn’t tell you much about what it’s like to actually work with.
Humanity’s Last Exam (HLE) is different:
It’s an expert-curated exam across math, natural sciences, engineering, economics, humanities, law, and more.
It mixes multiple choice and exact-match questions, many of which require several non-obvious reasoning steps.
A chunk of the questions are multimodal, forcing models to reason jointly over text and images.
Crucially, even the very best models today are still far from human expert level on HLE, and their confidence is often badly calibrated.
The authors explicitly ask people not to republish the raw questions, because they want HLE to stay a useful long-term benchmark. So in this post:
We don’t show the original wording of any question.
Instead, we describe five representative “HLE-style” tasks and how the models behave on them.
You can reproduce these patterns yourself using the public HLE dataset or similar problems from your own domain.
2. Four “thinking” models in 2025
We’re not comparing “chatbots” here, we’re looking at models pitched explicitly as reasoners: deep chain-of-thought, tools, long context, planning.
Gemini 3 (Pro + Deep Think)
Google presents Gemini 3 as its most capable model to date:
Stronger reasoning and multimodal understanding than the Gemini 2.5 generation.
Competitive scores on HLE without tools, plus excellent performance on GPQA, MMMU-Pro, Video-MMMU and other reasoning benchmarks.
A big focus on long-horizon, tool-calling agents: the “plan anything” story, including top results on planning benchmarks like Vending-Bench.
Gemini 3 also exposes a Deep Think mode that spends more compute and tokens on hard problems to squeeze out a bit more accuracy.
Kimi-K2 Thinking
Moonshot’s Kimi-K2 Thinking is an open-weight “thinking” model:
Mixture-of-experts architecture with a huge total parameter budget but a smaller active subset per token.
Long context (hundreds of thousands of tokens) and very heavy chain-of-thought by design.
Public analyses often show Kimi-K2 Thinking and its “Heavy” variant at or near the top on HLE and other reasoning benchmarks.
If you’ve ever seen a model spill out pages of internal monologue for one math problem: that’s the Kimi-style aesthetic.
Grok-4 / Grok-4.1
xAI’s Grok-4 line is pitched as:
A highly capable reasoning model with native tool use and internet search.
Strong on HLE, GPQA, and long-horizon tasks where agents must maintain coherent behavior over many steps.
Grok-4.1 adds more focus on “emotional” and creative intelligence, but still keeps the core reasoning strength.
Think of Grok-4.x as the model that really wants to be an agent: plan, search, act, reflect, repeat.
GPT-5.1 (GPT-5 family)
OpenAI’s GPT-5 family is the baseline most people reach for:
Very strong on broad benchmark suites: coding, reasoning, multimodal, long context.
When run in a high “reasoning effort” / “thinking” mode, it allocates more tokens and computes tough problems and tends to close the gap on advanced benchmarks like HLE and GPQA.
We’ll refer to GPT-5.1 Thinking as a GPT-5 variant running in that high-effort profile.
3. How we compared them (without leaking HLE)
The goal here wasn’t to build another leaderboard, but to see how these models behave on HLE-style tasks.
At a high level:
We selected a set of representative HLE questions (math, multimodal physics, long science passages, game theory, planning).
For each question, we used a consistent “exam-mode” prompt:
“Reason step by step.”
“Explain your thinking.”
“End with Final answer: … and Confidence: ….”
We ran exactly the same question and scaffold across:
Kimi-K2 Thinking
Grok-4.1
GPT-5.1 Thinking
Gemini 3 Pro (and where available, Gemini 3 Deep Think)
All of this was wired through the TrueFoundry AI Gateway:
One endpoint where we plug in OpenAI, Google, xAI, Moonshot and 1000+ other models.
One place to log responses, tokens, latency and cost per call.
One set of auth, quotas and guardrails across vendors.
More on that later — for now, let’s look at the five case studies.
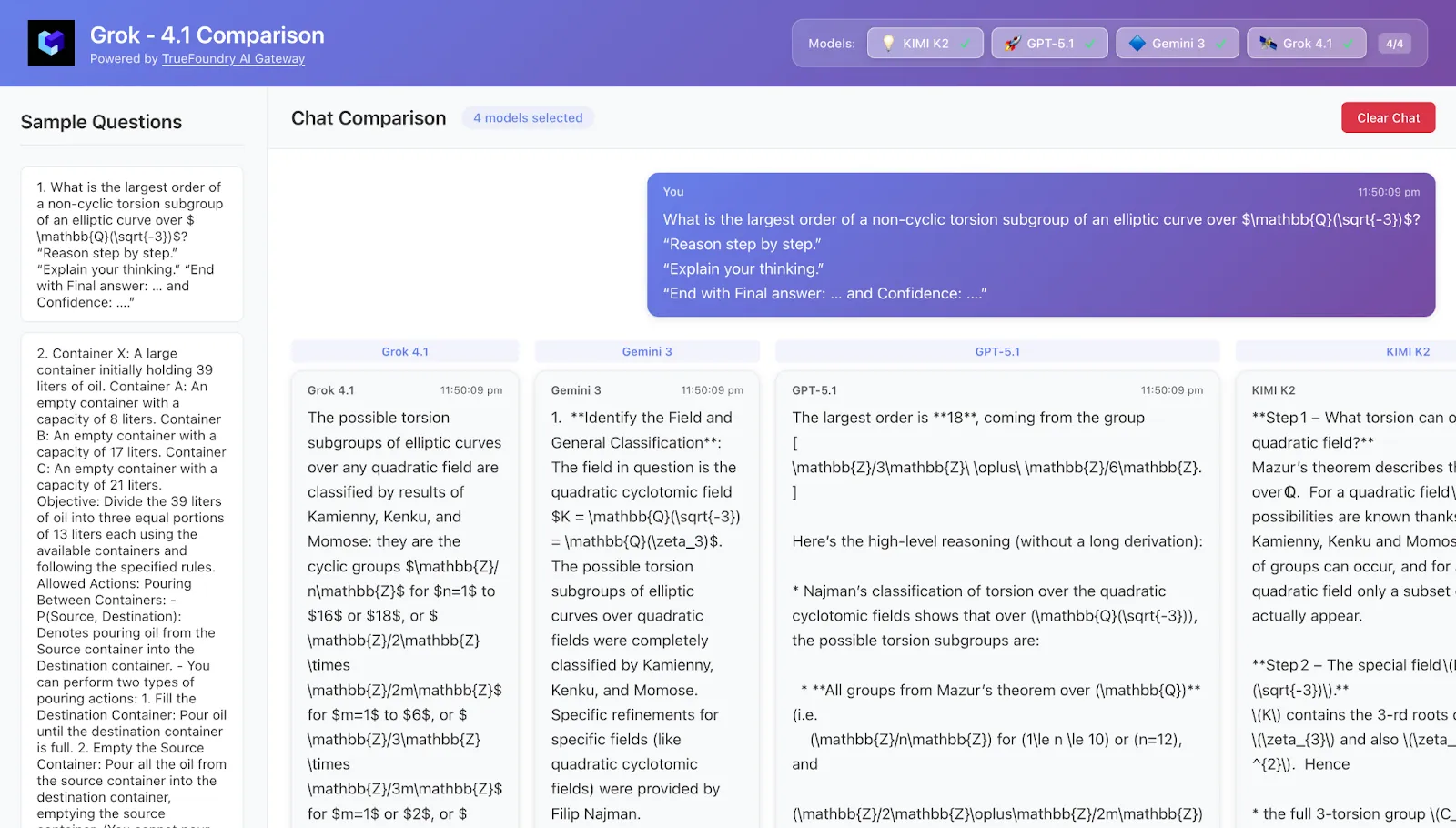
4. Case Study 1 – Deep math: accuracy vs token-hungry thinking
Task A graduate-level math problem (think number theory / combinatorics):
Single short answer (an integer or simple expression).
Needs ~4–6 non-obvious reasoning steps.
Very hard to guess correctly without actually working it through.
What we look at
Does the model set up the structure correctly (e.g., right theorem / classification)?
Does it carry the reasoning to the end without losing a minus sign?
How many tokens does it burn to get there?
How calibrated is its confidence?
Typical patterns observed
Kimi-K2 Thinking
Extremely long chain-of-thought: recalls relevant theorems, explores multiple candidate approaches, often branches and backtracks.
Very strong on accuracy, especially in “Heavy” mode, but often spends significantly more tokens than others.
Self-reported confidence is frequently 90–100%, even on quite delicate problems.
Grok-4.1
Bold and exploratory: quickly sketches an intuitive answer, then tries to justify it.
When right, it looks brilliant; when wrong, it can be very confident.
GPT-5.1 Thinking
Good structure: clearly enumerates cases, labels them, and refers back cleanly.
Often slightly more modest in its confidence estimates, especially when the problem requires multiple deep facts.
Gemini 3 (Pro / Deep Think)
Multi-step reasoning, but noticeably more concise than Kimi-K2’s walls of text.
Deep Think mode closes much of the HLE gap with Kimi/Grok, while staying somewhat more measured in its explanations.
Takeaway If you’re chasing every extra point on HLE-style math, Kimi-K2 Thinking and Grok-4.x feel like the leaders, with Gemini 3 Deep Think close behind. If you care about cost and speed as much as raw accuracy, Gemini 3 and GPT-5.1 Thinking are attractive because they achieve similar results while being less token-hungry.
5. Case Study 2 – Multimodal physics: “actually look at the diagram”
Task A diagram-heavy physics / engineering question:
A circuit diagram, free-body diagram, or optical setup is embedded as an image.
The question asks for a numeric answer (e.g., current, angle, time).
You can’t answer correctly without parsing the figure properly.
What we look at
Does the model describe the diagram in a way that matches the picture?
Does it make assumptions not present in the image?
How well does it combine image and text into a coherent derivation?
Typical patterns observed
Gemini 3
Very deliberate about the image itself: “the arrow points left”, “there are three resistors in series”, “the mass is attached by two springs”.
Fewer hallucinations about the diagram’s content.
Overall feels like the most grounded in its multimodal reasoning.
GPT-5.1 Thinking
Strong multimodal understanding, but often less explicit: it uses the diagram correctly, yet doesn’t always describe it in detail.
When it fails, it’s usually from a mis-read of the text rather than the image.
Kimi-K2 Thinking
Once the givens are correct, the physics is solid.
But under pressure, it can mis-count elements in the diagram (e.g., number of components) and then propagate that error through a very long derivation.
Grok-4.1
Similar to GPT-5.1 in style: intuitive, often right, but occasionally overconfident on a misinterpreted line or label.
Takeaway If a lot of your HLE-style workload involves diagrams, schematics, or visual puzzles, Gemini 3’s multimodal stack is a standout. GPT-5.1, Kimi-K2 and Grok-4.1 are all capable, but more prone to “seeing” details that aren’t quite there.
6. Case Study 3 – Long-context science: reading, not just solving
Task A long, dense science passage (biology / medicine / chemistry):
Several paragraphs describing an experiment, methods, results and caveats.
Then a question that requires integrating information across the whole passage, not just the last paragraph.
What we look at
Does the model summarize the passage accurately?
Does it keep track of variables, conditions and exceptions across paragraphs?
Does it correctly identify which details actually matter to answer the question?
Typical patterns observed
Gemini 3
Good at compressing long passages into laser-focused bullet points.
Tends to restate key facts, then reason “from the notes” to the answer.
Rarely contradicts itself when referencing earlier parts of the passage.
GPT-5.1 Thinking
Excellent at tracking variables and experimental setups; feels like a careful TA.
Often the cleanest “read → summarize → infer” pipeline.
Kimi-K2 Thinking
Hyper-detailed: repeats a lot of the passage and sometimes re-derives background theory.
That depth is useful, but the sheer length means the occasional drift or internal contradiction can creep in.
Grok-4.1
Very good at extracting practical implications (“this suggests treatment A is preferable when…”).
Sometimes glosses over rare edge cases mentioned in the text.
Takeaway For HLE-style “read this and actually understand it” questions, Gemini 3 and GPT-5.1 Thinking are particularly strong: they summarize crisply, preserve important details, and keep the logic straight. Kimi-K2 and Grok-4.1 are also capable, but their longer narratives can introduce more opportunities for drift.
7. Case Study 4 – Game theory & microeconomics: who reasons like a TA?
Task A microeconomics / game theory question:
Multiple players, a small action set, and payoff descriptions.
You’re asked to find equilibria, characterize strategies, or compare welfare outcomes.
What we look at
Does the model enumerate all relevant cases?
Does it keep the logic consistent from case analysis to final answer?
Is it aware of subtleties like mixed strategies, dominance, or symmetry?
Typical patterns observed
Kimi-K2 Thinking
Reads like a grad student TA: lots of case-by-case analysis, explicit construction of counterexamples, careful consideration of edge cases.
Very strong when you want to see the entire reasoning tree.
Grok-4.1
Intuitively excellent at incentive reasoning (“if player A deviates, they gain X, so this can’t be an equilibrium”).
Occasionally locks into an intuitive equilibrium early and needs to be nudged to reconsider.
GPT-5.1 Thinking
Systematic: labels cases (Case 1, Case 2, …), summarizes findings, and ties them together smoothly.
Good balance between depth and brevity.
Gemini 3
Similar to GPT-5.1 in structure, with a bit more tendency to backtrack explicitly (“let’s reconsider the assumption that…”), especially in a Deep Think–style mode.
Takeaway On game-theoretic HLE questions, Kimi-K2 Thinking and Grok-4.1 feel closest to a human teaching assistant: lots of explicit casework and intuitive discussion. Gemini 3 and GPT-5.1 get to the answer with less wandering, which can be preferable when you’re piping outputs directly into code or decision pipelines.
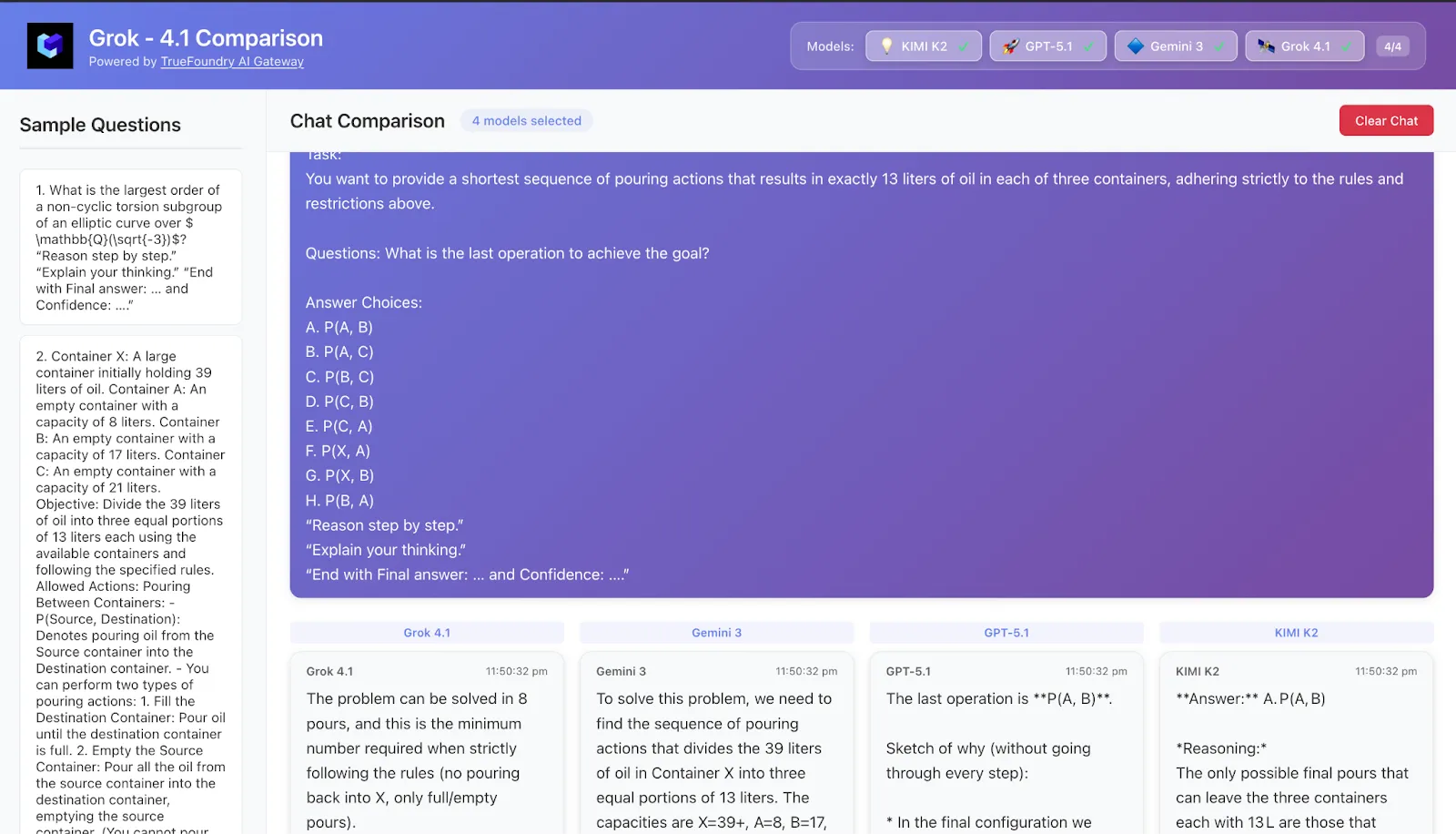
8. Case Study 5 – Planning problems: mini-agents inside a prompt
Task A planning / operations-research-style puzzle:
Several containers, capacities, and pouring rules, or a scheduling / inventory management setup.
You must choose a policy or sequence of actions that reaches a goal in minimal steps under constraints.
What we look at
Does the model set up the state space clearly?
Does it simulate sequences correctly without forgetting earlier actions?
Does it stick to the constraints it itself stated?
Typical patterns observed
Grok-4.1
Very agent-like: explicitly writes out states (“after step 3: inventory is X, Y, Z”), checks each against the goal, and course-corrects when needed.
Feels closest to using a real planning agent inside a single prompt.
Gemini 3
Similar planning style: restates the objective and constraints, proposes a policy, then simulates several steps.
Particularly good at not losing track of state over longer sequences, which aligns well with its long-horizon / Vending-Bench pitch.
GPT-5.1 Thinking
Good conceptual planning, but more prone to small arithmetic or bookkeeping errors across many steps.
When asked to guarantee “shortest sequence”, sometimes it needs a second try.
Kimi-K2 Thinking
Provides lots of detailed simulation, but the combination of long CoT + complex state sometimes leads to small inconsistencies (e.g., a quantity silently changing between steps).
Takeaway On planning-flavored HLE tasks, Grok-4.1 and Gemini 3 feel like the most reliable mini-agents. Kimi-K2 and GPT-5.1 are very capable, but their long reasoning traces can sometimes work against them when state tracking is critical.
9. So… who “wins” Humanity’s Last Exam?
If you look only at headline HLE percentages, Kimi-K2 Thinking (particularly Heavy variants) and some Grok-4 configurations currently sit at or near the top, with Gemini 3 Deep Think close behind and GPT-5 Pro a touch lower.
But HLE is messy in the best way:
Accuracy is still far below human experts.
Confidence is often miscalibrated: models can be very sure and very wrong.
Different domains (math vs science vs planning vs humanities) show different winners.
From the five case studies:
Kimi-K2 Thinking
Best when you want maximum depth and are comfortable paying in tokens and latency to squeeze out every last bit of performance.
Grok-4.1
Shines on planning and agent-like reasoning; if your tasks look like simulations or multi-step business decisions, Grok feels very natural.
GPT-5.1 Thinking
A strong, safe default: great long-context reading, generally clean structure, and very easy to integrate into existing systems.
Gemini 3 (Pro + Deep Think)
Particularly compelling on multimodal reasoning, structured reading comprehension, and planning — and the “Plan anything” pitch isn’t just marketing; it shows up in how it handles long, stateful problems.
There’s no single winner for Humanity’s Last Exam. The “best” model is the one that fails least badly on your actual tasks, under your actual constraints.
10. How we ran this through TrueFoundry AI Gateway
Under the hood, we didn’t build four separate integrations. Everything went through the TrueFoundry AI Gateway (truefoundry.com/ai-gateway):
One endpoint for OpenAI (GPT-5.1), Google (Gemini 3), xAI (Grok-4.x), Moonshot (Kimi-K2), and hundreds of other models.
Centralized observability: logs for prompts, responses, tokens, latency, and errors across vendors.
Built-in governance & security: RBAC, audit logs, and deployment options that keep data in your cloud or on-prem.
On the experimentation side, that meant:
We wired our evaluation harness once to the Gateway.
We registered gpt-5.1-thinking, kimi-k2-thinking, grok-4.1, gemini-3-pro and gemini-3-deep-think as just different model IDs.
Swapping between them was a one-line config change, not a new SDK integration.
11. Try Gemini 3 (and the rest) on your own “last exam”
If you’d like to reproduce (or challenge) the patterns in this post:
Pick your exam.
Use HLE or an internal “last exam” built from your own domain: research questions, support tickets, code reviews, incident post-mortems.
Run it through multiple models.
Point your evaluation harness at the TrueFoundry AI Gateway and run the same prompts across Gemini 3, Kimi-K2 Thinking, Grok-4.1 and GPT-5.1 Thinking.
Compare in one place.
Look at correctness, reasoning quality, token usage, latency, and cost side-by-side.
Decide which “thinking” model actually earns its grade on your tasks.
Because in 2025, the only benchmark that really matters isn’t HLE, MMLU or GPQA — it’s the exam that looks like your own work. And you don’t have to pick a single model on faith when you can wire up four of them behind one gateway and let the results speak for themselves.
Frequently Asked Questions
What is the difference between Kimi K2 and Gemini 3?
Gemini 3 from Google focuses on multimodal understanding and strong tool-calling capabilities with a Deep Think mode. Kimi-K2 Thinking, an open-weight model, is known for its extensive long context and detailed chain-of-thought reasoning. Understanding kimi k2 vs gemini 3 reveals distinct approaches to advanced AI problem-solving.
What is kimi K2 thinking best for?
Kimi-K2 Thinking is best for complex reasoning and deep problem-solving tasks. With its long context and heavy chain-of-thought by design, **kimi k2** excels at challenges requiring extensive internal monologue, like advanced math problems and benchmarks such as Humanity's Last Exam, often ranking among top models.
Gemini 3 vs GPT-5: which is better?
Our blog delves into Gemini 3 vs GPT-5.1 by assessing their performance on Humanity's Last Exam. We found 'better' depends on the specific reasoning task and model behavior. TrueFoundry's analysis, conducted via our AI Gateway, highlights their unique problem-solving approaches, helping you determine the optimal fit for your AI solutions.
Gemini 3 vs Grok-4: which model performs better?
When comparing Gemini 3 vs Grok-4, both excel as powerful reasoning agents, demonstrating strong performance on complex tasks like Humanity's Last Exam. Gemini 3 features advanced multimodal understanding and a Deep Think mode, while Grok-4 focuses on native tool use and agentic capabilities. Optimal performance often depends on the specific task's requirements.
Which AI model is best for reasoning tasks?
For complex reasoning tasks, models like Gemini 3, Kimi-K2 Thinking, and GPT-5.1 demonstrate strong capabilities. Our blog evaluates how each performs across various challenges, helping you understand their specific strengths. The optimal choice when comparing gemini 3 vs kimi k2 thinking vs gpt 5 ultimately depends on your project's unique demands and the type of reasoning required.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.














.webp)
















.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




