














June 20, 2026
|
5 min read

Published: May 29, 2026

Blazingly fast way to build, track and deploy your models!
AI infra isn’t a single monolith now, it has evolved into an ecosystem of models, agents, tools, data stores and control planes. AI infrastructure has evolved beyond a single model or platform. Today’s enterprise stack is a sprawling ecosystem of LLMs, agents, vector databases, orchestration frameworks, and control planes — each with its own APIs, formats, and governance rules. At enterprise level this heterogeneity creates both opportunities and problems, teams can pick the best model for a job, but different providers speak different APIs, return different shapes, and need different governance.
Enterprises want the flexibility to use the best model for each task, but every provider speaks a different API, returns a different schema, and requires different credentials. Without a unifying layer, teams end up writing brittle integrations and managing scattered observability and compliance.
The answer is architectural, not procedural.
AI interoperability must be designed — not patched. And the key enabler of that design is the AI Gateway: a central layer that standardizes how applications interact with models, tools, and agents. An AI Gateway acts as the “common language” of your AI ecosystem. It normalizes inputs and outputs, enforces security and compliance policies, routes traffic intelligently, and provides unified observability. In short, it turns fragmented AI infrastructure into a cohesive, governed system.
In very simple terms AI Interoperability is the ability of AI systems to work and integrate together in a seamless manner. This in turn means your stack follows common interfaces and formats, for example handing over a task from model A to model B should not require schema level changes, or change in API configurations. AI interoperability lets “different models, APIs, data formats, and systems work together without requiring custom code for every integration. In other words, you can switch between providers, combine multiple LLMs, or upgrade models—all without breaking your existing infrastructure.
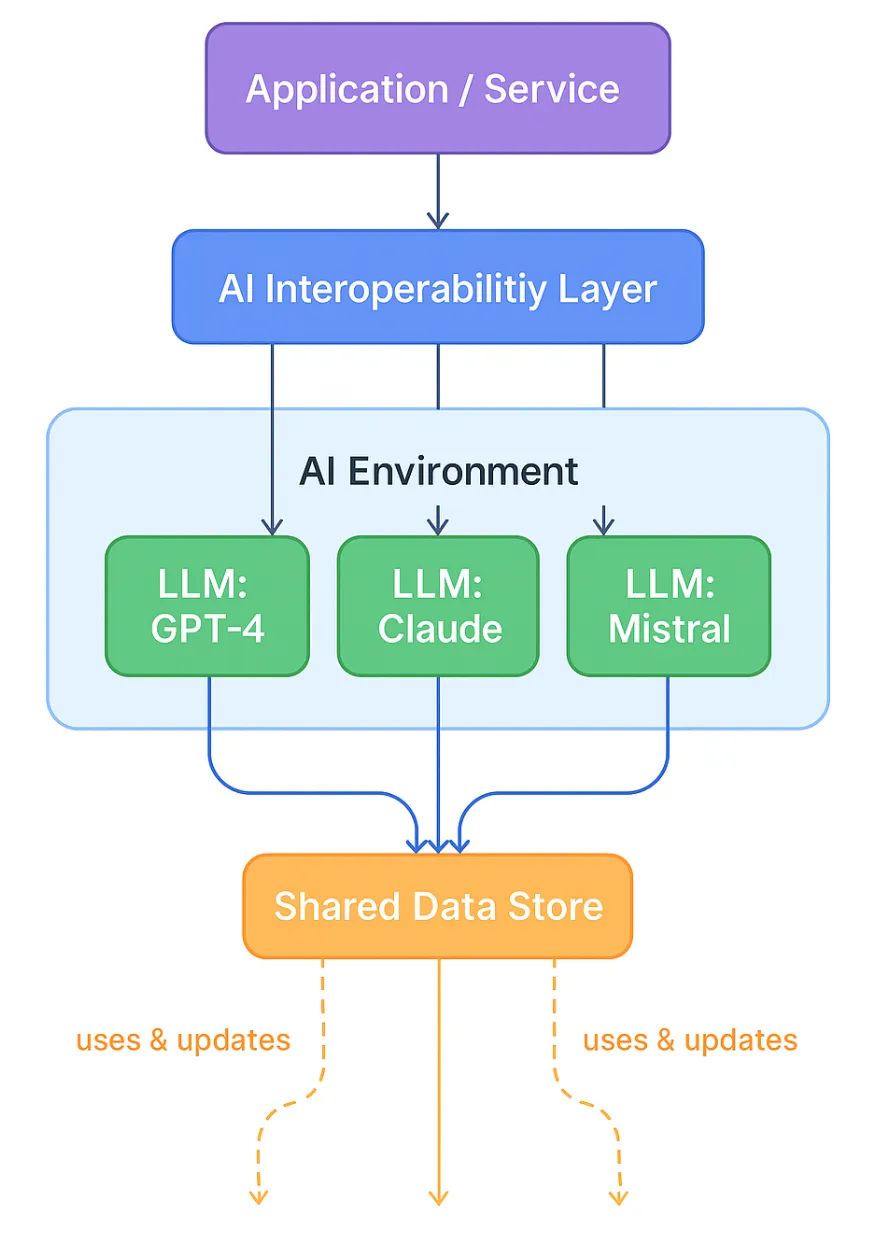
Another aspect to AI Interoperability is making “different AI systems, models, and agents work together, seamlessly exchanging data, making decisions collaboratively, and triggering actions across platforms”. This goes beyond just APIs: it means AI agents share context and language, coordinate their tasks, and reuse each other’s outputs. Think of it like connected workflows in an organization – your email, CRM, and project tracker each have their own job, but when they share data they form a smooth automated process. AI interoperability similarly reduces silos by letting models and tools talk a common language.
AI Interoperability is all about building flexible and modular systems with :
Flexible and modular systems are good to have but hard to maintain, why do we even need AI Interoperability?
The answer is short and simple, and let’s understand it with a simple example. Suppose you want to use 2 different models Gemini, and Claude for a single task, Gemini specializes in handling very long context windows, whereas Claude specializes in depth reasoning problems, having a single unified interface which lets you switch models easily, eliminates your code level changes, and makes your application more robust due to diversity of tasks it can handle. Another good example is how some small models might help in handling easier queries, and save a ton of cost, as complex reasoning LLMs can shoot up your cost pretty quickly.
Interoperability reduces:
In a world where new models appear weekly, interoperability ensures your stack remains adaptive, resilient, and future-proof, improves productivity, decision quality, amplifies AI strengths, makes AI orchestration faster and brings down integration costs.
Enterprise-grade interoperability can be understood across three layers:
Additional building blocks include:
A simple example:
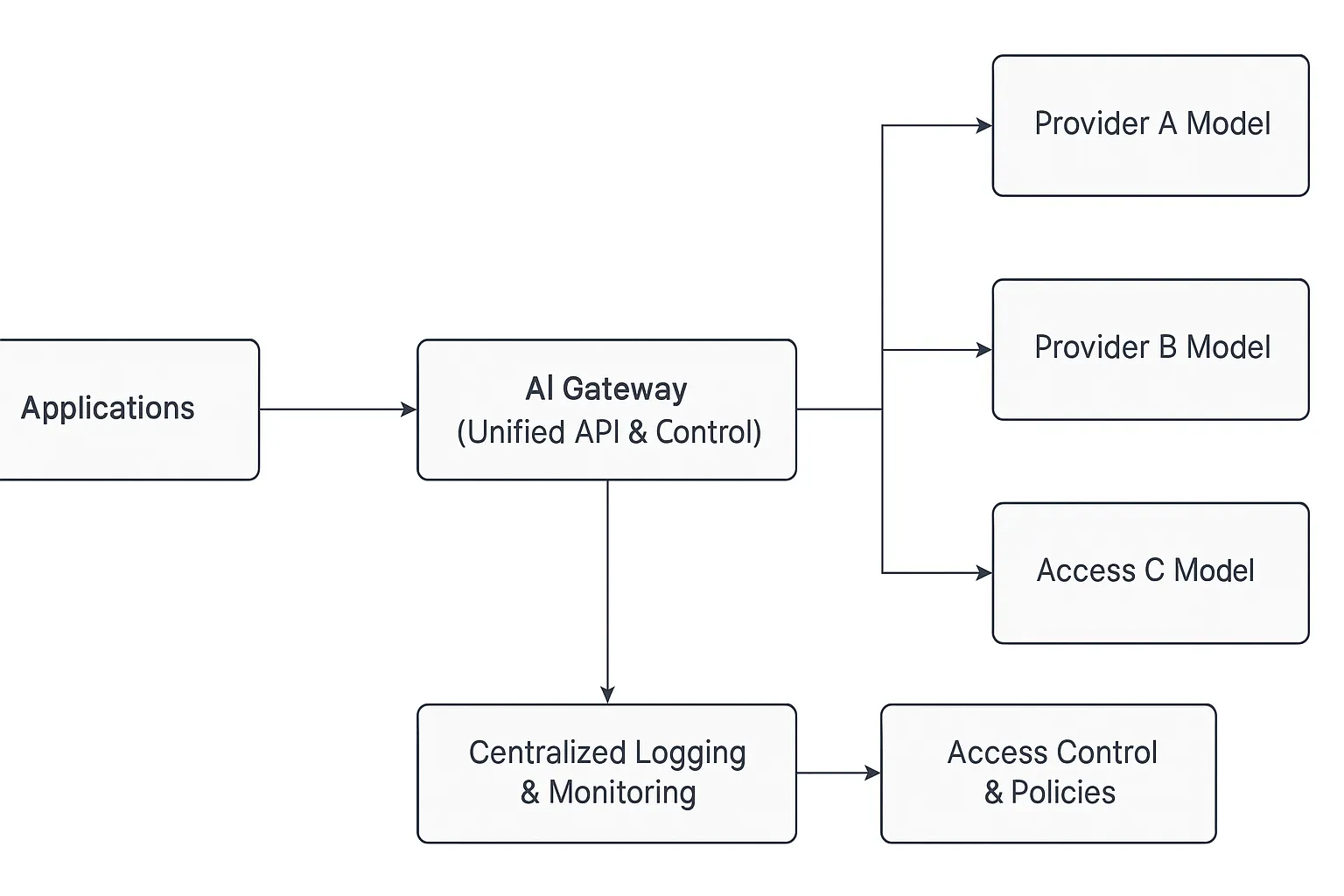
Instead of applications managing multiple connectors, the AI Gateway exposes one API endpoint. It handles key management, schema normalization, and routing logic internally — letting developers call any model through the same interface.
There are a few major challenges in achieving integration of diverse AI systems. Here are a few explained :
def normalize_prompt(template, vars, model_family):
prefix = {
"gpt": "SYSTEM: enterprise assistant; JSON_ONLY=true\n",
"claude": "Human: enterprise assistant\nAssistant:",
"mistral": "<s>[INST] enterprise assistant [/INST]"
}.get(model_family.lower(), "")
safe_vars = {k: str(v).replace("{", "{{").replace("}", "}}") for k,v in vars.items()}
return prefix + template.format(**safe_vars)
from opentelemetry import trace
tracer = trace.get_tracer(__name__)
def log_call(model_name, request_meta, response_meta):
with tracer.start_as_current_span("model_call") as span:
span.set_attribute("model.name", model_name)
span.set_attribute("request.tokens", request_meta.get("tokens",0))
span.set_attribute("response.latency_ms", response_meta.get("latency_ms",0))
def route_request(task_type: str, cost_limit: float, latency_target: int):
routing_rules = {
"reasoning": "claude-3",
"summarization": "gpt-4o-mini",
"bulk_text": "mistral-7b",
}
# Select model based on task type
model = routing_rules.get(task_type.lower())
# Apply policy overrides (cost and latency aware)
if cost_limit < 0.01:
model = "mistral-7b" # cheapest
elif latency_target < 1000:
model = "gemini-flash" # fastest
elif not model:
model = "gpt-4o" # default fallback
return model
import hashlib, json
def secure_payload(data, key):
sanitized = {k:v for k,v in data.items() if k not in ("pii","secrets")}
encrypted = hashlib.sha256(json.dumps(sanitized).encode() + key.encode()).hexdigest()
return {"data_hash": encrypted, "meta": {"secured": True}}
If done right, AI interoperability delivers strong benefits to both technology and business.
AI interoperability turns isolated capabilities into a cohesive system. It upgrades your AI from a set of smart tools into a smart system.
An AI Gateway is a middleware that centralizes components that makes interoperability practical. The gateway provides a single entry point and handles the diversity of models and tools behind the scenes. It provides a single, consistent entry point for all AI interactions and handles provider-specific quirks behind the scenes. In effect, it unifies the AI ecosystem. The gateway abstracts away each provider’s quirks (like different endpoints, credentials and formats), enabling seamless interoperability.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

TrueFoundry’s AI Gateway is built precisely for this.
It acts as the proxy layer between your applications and model providers or MCP servers, offering access to 1,000+ models through a single, unified interface.
Key capabilities include:
By centralizing these functions, TrueFoundry eliminates the need for teams to build connectors, write routing logic, or manage separate dashboards. The gateway becomes the nervous system of your AI infrastructure, enforcing consistency, security, and reliability across every model and agent.
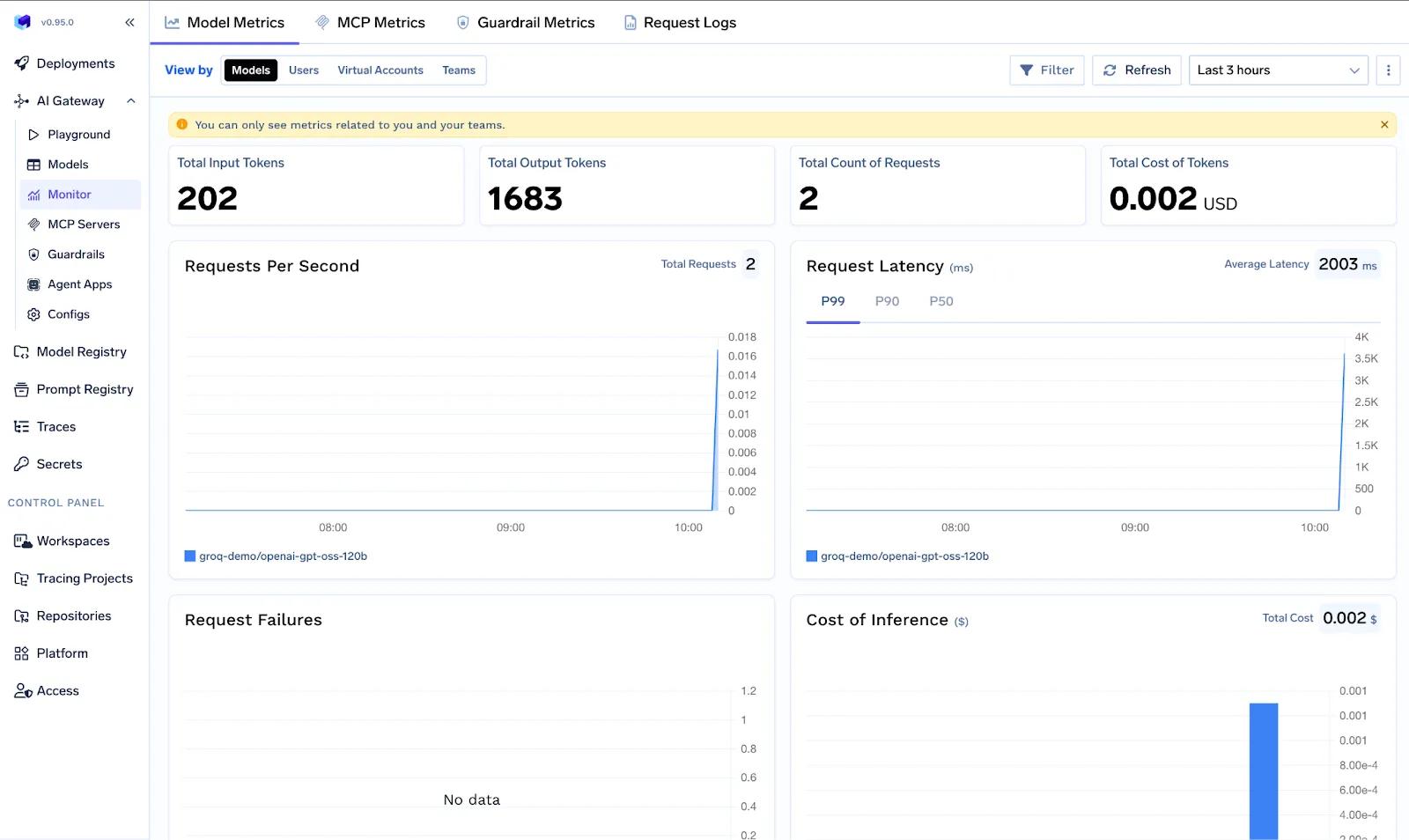
TrueFoundry’s platform offers access to 1000+ models using one interface and manages security and governance centrally. TrueFoundry’s feature list highlights exactly the interoperability enablers: unified API calls, API key management, fine-grained access control, rate limiting per user/model, load balancing across model instances, cost budgeting, content guardrails, and consolidated observability. These features show how an AI Gateway standardizes control: all models are now governed by one set of policies and metrics.
By centralizing these concerns, an AI gateway dramatically simplifies interoperability. Instead of building connectors in every app, you configure models in one place. The gateway can dynamically route queries (e.g. by adjusting traffic weights) and even failover to backup models if one is down. It becomes the control plane for enterprise AI, as multiple sources have noted. For instance, one analysis on AI gateways points out that they introduce features beyond classic API proxies: token-based rate limiting, content review on responses, multi-backend load balancing, and session context management.
By handling these tasks, AI gateways enable interoperability by design. They are the interface that makes a polyglot AI stack feel like a single platform.
Adopting AI interoperability is a journey. The following best practices can guide teams through design and implementation:
The key is to proactively design for connectivity rather than retrofitting solutions later. History shows that early standardization pays off – as one analysis notes, waiting until systems are entrenched makes integration far harder.
AI interoperability is part of infrastructure. As AI systems multiply across providers, modalities, and control planes, the ability to make them talk to each other cleanly decides whether your organization scales or stalls. The old approach of wiring every model manually doesn’t hold up when new APIs appear every month and compliance rules keep tightening.
That’s exactly where AI Gateway change the game. Platforms like TrueFoundry turn what used to be an integration nightmare into a governed, observable, and pluggable control layer. One API, one policy surface, one audit trail — no matter how many models or agents you plug in. Instead of teams reinventing connectors and logging for every new provider, the gateway becomes the operating fabric of enterprise AI. It routes traffic smartly, enforces security and rate limits automatically, and exposes a unified monitoring plane that works across all vendors.
This is the foundation for sustainable AI adoption - where innovation doesn’t come at the cost of chaos. Interoperability, when built into the architecture, unlocks genuine flexibility: you can pick the right model for each task, experiment faster, and keep costs predictable without losing control.
As enterprises evolve from deploying a single model to orchestrating dozens, those that treat interoperability as a first-class design goal not an afterthought will move faster, spend smarter, and stay future-proof. AI Gateways are not just middleware; they’re the backbone of the multi-model era, turning a fragmented AI stack into one cohesive, governed system built to last.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.









.webp)
.webp)
.webp)
.webp)
.webp)

.webp)

.webp)

.webp)