
تعلن TrueFoundry عن استحواذها على Seldon AI، موسعة بذلك لوحة التحكم الخاصة بها للذكاء الاصطناعي للمؤسسات. البيان الصحفي الكامل →

احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.










AI solution to assess and improve the reading skills of children in underserved communities
Wadhwani AI is a non-profit organization that works on multiple turnkey AI solutions for underserved populations in developing countries.
Through the Vachan Samiksha project, the team is developing a customized AI solution that teachers in rural India can use to assess the reading fluency of students and develop a personalized contingency plan to improve the reading skills of each student.
The team had deployed the solution in primary schools for conducting pilots. However, the team was facing the following issues that needed to be solved before the project’s scope was expanded to more schools and students:
TrueFoundry team partnered with the team to solve these problems. Using the TrueFoundry platform, the team was able to:
Wadhwani AI was founded by Romesh and Sunil Wadhwani (Part of the Times100 AI list) to harness AI to solve problems faced by underserved communities in developing nations. They partner with government and global nonprofit bodies worldwide to deliver value through the solution. As a not-for-profit, Wadhwani AI uses artificial intelligence to solve social problems in the fields of agriculture, education, and health, among others. Some of their projects include:
Wadhwani AI also works with partner organizations to assess their AI-readiness, which is their ability to create and use AI solutions effectively and sustainably. Wadhwani AI’s work aims to use AI for good and to improve the lives of billions of people in developing countries.
Reading skills are fundamental to any child's educational foundation. Unfortunately, many students from the rural and underprivileged regions of India and other developing nations lack these skills. To solve this problem on a foundational level, the Wadhwani AI team has developed an AI-based Oral Reading Frequency tool called the Vachan Samiksha.
The tool deploys AI to analyze every child’s reading performance. It is mostly targeted towards rural and semi-urban regions of the country at the moment and is being used across age groups. To make the solution generalizable for most of the country, the team has built an accent-inclusive model to assess regional languages and English. Manual assessment of these skills have their biases and are often inaccurate.
The solution is served to the users (teachers of target schools) through an app that invokes the model that is deployed on the cloud. The student is made to read a paragraph, which is recorded by the application and sent to the cloud. On the cloud, the model assesses reading accuracy, speed, comprehension, and other complex learning delays that could be missed in a normal evaluation. Besides assessing these skills, the application also creates a personalized learning plan for each student to facilitate their learning and also creates demographical reports for macro-level actions by the government authorities. The team had deployed the model for the pilot with the cloud provider's managed ML service
When we started our collaboration with the Vachan Samiksha team within Wadhwani AI, the team had been leveraging the native MLOps stack of their cloud provider to deploy the model for its pilot with the Education Department of Gujarat.
Their infrastructure setup was as follows:
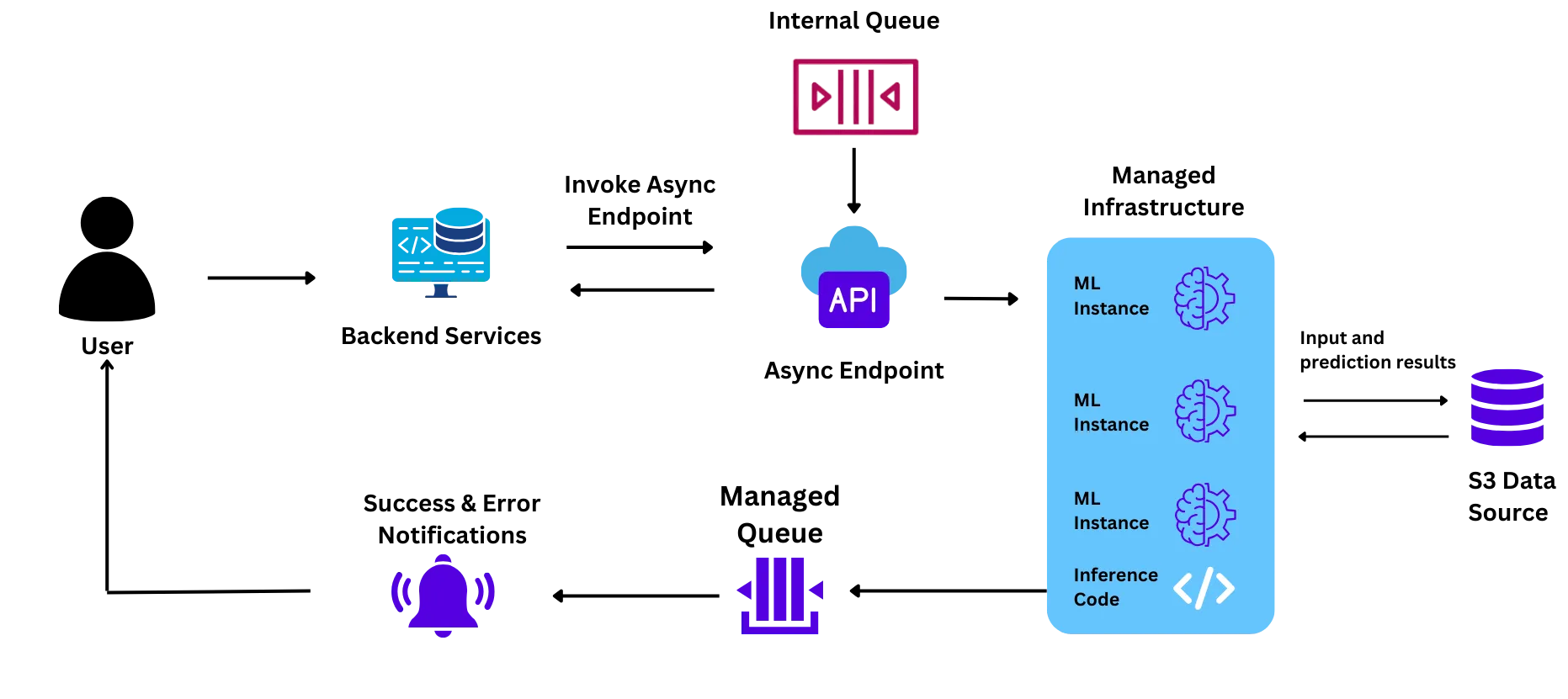
The team faced challenges with this setup while trying to conduct the first pilot, which motivated them to try out other solutions:
The pilot was anticipated to run at a huge scale (~6 Million students in a month). However, the team did not have confidence that the managed ML service would be able to support this scale because:
During the pilot, the team faced issues with the scaling speed, and some pods did not come up as expected. However, to resolve the issue, the team contacted the cloud provider's representatives, who then contacted the technical team. This induced a delay in the system and caused a delay in the pilot.
When request traffic increased during the pilot, the pods were required to scale horizontally (Spin up new nodes that could pick up and process some of the requests from the queue). This process took ~9-10 minutes for each new pod that was spun up, resulting in delayed responses and a poor experience for the end user.
GPU instances are very expensive due to the global shortage of chips. Add on top of this the 20-40% markup for ML instances that the cloud provider puts. This made the cost of the instances very high and infeasible for the team at the scale that they wanted to run the project.
When we met the Vachan Samiksha team, they were in the period between their first pilot and the second. The pilot was less than a week away and we had to:

During the time before the pilot:
Our team helped the Wadhwan AI Team install the platform on their own raw Kubernetes. The control plane and the workload cluster were both installed on their own infrastructure. All of the Data, UI elements to interact with the platform, and the workload processes for training/deploying the models remained within their own VPC. The platform also complied with all the company's security rules and practices.
We helped the team understand how the different components interact during the training and onboarding process. We walked them through how to set up resources, configure autoscaling, and deploy the model.
The Wadhwani AI team was able to migrate the application on its own with minimal help from the TrueFoundry team. This was done in a 1-hour call with the team.
After the application was deployed, the team started testing production level load on it. The team independently scaled up the application to more than 100 nodes through a simple argument on TrueFoundry UI which is 5X their previous highest achievable scale. They also tried benchmarking the speed of node scaling, which was much (3-4 X) faster than that provided by their .
With the load tests done, the team deployed the pilot application and was prepped for rolling it out in the second phase of the pilot which was rolled out to 1000 schools, 9000 Teachers, and over 2 Lakh students.
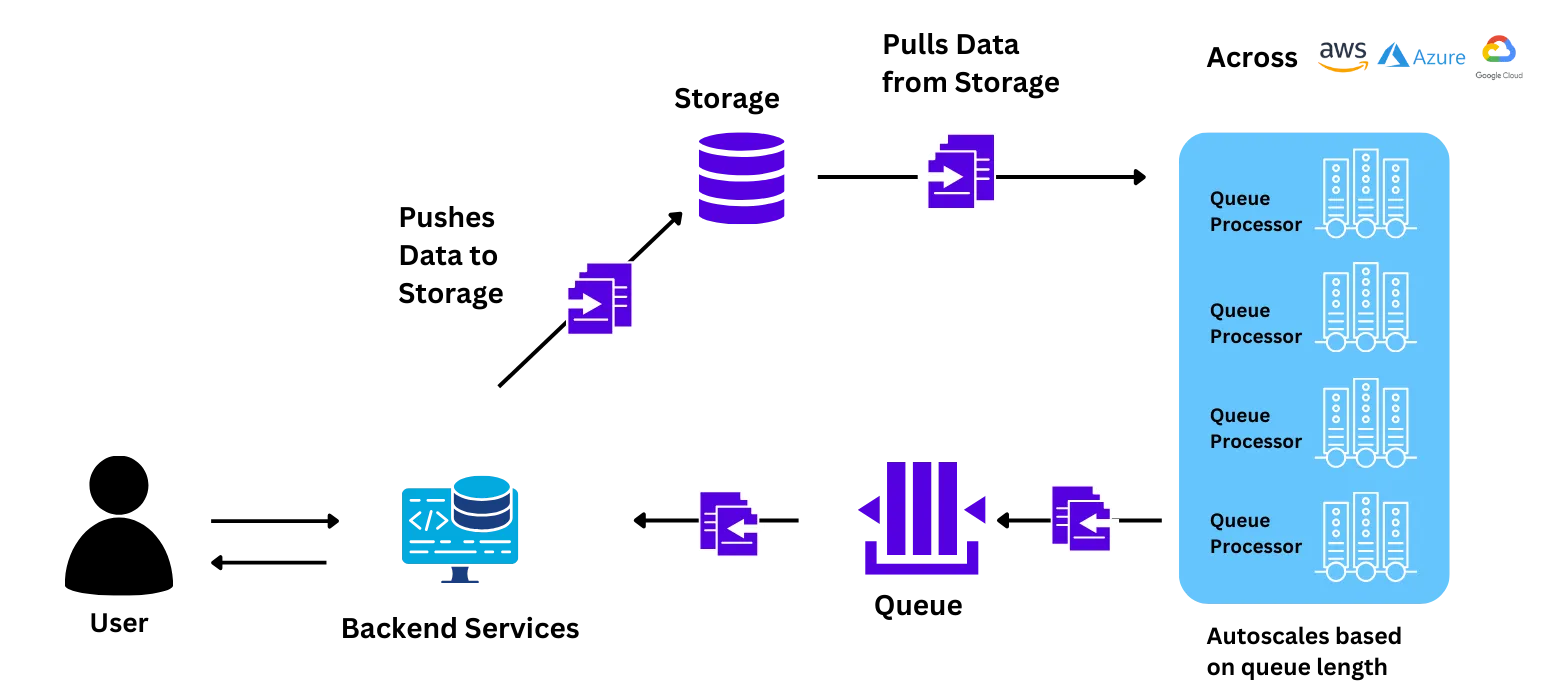
With a minimal effort of less than 10 hours, the Wadhwani AI team was able to realize a significant improvement in speed, control, and costs. Some of the major changes that they realized were:
The Data Scientists and Machine Learning Engineers were able to configure multiple elements which were either difficult for them to do through the cloud provider's console or they had to rely on the engineering team:
Based on queue length and increasing the maximum number of replicas/nodes to 70 instead of the previous limit of 20
Since most of the pilot traffic came in during school hours when the teachers interacted with the students, there were minimal requests, if any, during the evening and nigtionsht. The teamconstant, was able to set up a scaling schedule with which the pods scaled down to a minimum during the down hours (evening and nights). This saved about 15-20% of the pilot cost.
The team could easily monitor the traffic, resource utilization, and responses directly from the TrueFoundry UI. They also received suggestions through the platform whenever there was an overprovisioning or underprovisioning of resources
لاختبار قابلية التوسع باستخدام TrueFoundry، أرسل الفريق دفعة من 88 طلبًا إلى التطبيق وقارنوا أداء خدمة التعلم الآلي المُدارة لمزود السحابة مقابل TrueFoundry. تم الحفاظ على جميع إعدادات النظام مثل منطق التوسع (بناءً على طول قائمة الانتظار المتراكمة، والعدد الأولي للعقد، ونوع المثيل، وما إلى ذلك).
أدركنا أن TrueFoundry يمكنه التوسع بنسبة 78% أسرع من خدمة التعلم الآلي المُدارة، مما وفر للمستخدم استجابات أسرع بكثير. كما انخفض الوقت المستغرق من البداية إلى النهاية للاستجابة للاستعلام بنسبة 40% مع TrueFoundry.
انخفضت التكلفة التي كان يتكبدها الفريق للمشروع التجريبي بنسبة 50% تقريبًا بالانتقال إلى TrueFoundry، وقد تحقق ذلك بفضل العوامل المساهمة التالية:
بينما كانت خدمة التعلم الآلي المُدارة محدودة بتوفر مثيلات وحدات معالجة الرسوميات (GPU) في نفس منطقة مزود السحابة، يمكن لـ TrueFoundry إضافة عقد عاملة إلى النظام يمكن أن تكون عبر أي منطقة أو مزود سحابي.
هذا يعني أن:
توفر TrueFoundry تكاملاً سلساً مع أي أداة يرغب الفريق في استخدامها. مع مزود الخدمة السحابية، كان هذا الأمر محدودًا بخيارات التصميم التي اتخذها المزود وتكاملاته الأصلية. على سبيل المثال، أراد الفريق استخدام NATS لنشر الرسائل، وهي خدمة لم يقدمها مزود الخدمة السحابية الأصلي حاليًا. جعل TrueFoundry اتخاذ هذه الأنواع من الخيارات أمرًا سهلاً للغاية لفريق وادهواني للذكاء الاصطناعي.







أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.



