














August 27, 2025
|
5 min read

Published: March 16, 2026

Blazingly fast way to build, track and deploy your models!
The ML infrastructure landscape is filled with some of the most impressive solutions out there to simplify the ML pipeline. TrueFoundry can be a solution if you relate to some of the problems mentioned below:
The biggest reason we have found about delays in timelines is dependency between teams and lack of skillsets with different personas. TrueFoundry makes it easy for Data Scientists to train and deploy on Kubernetes using Python. It also allows infra teams to setup security constraints and cost budgets. In most companies we have talked to, the flow of implementation is something like below:
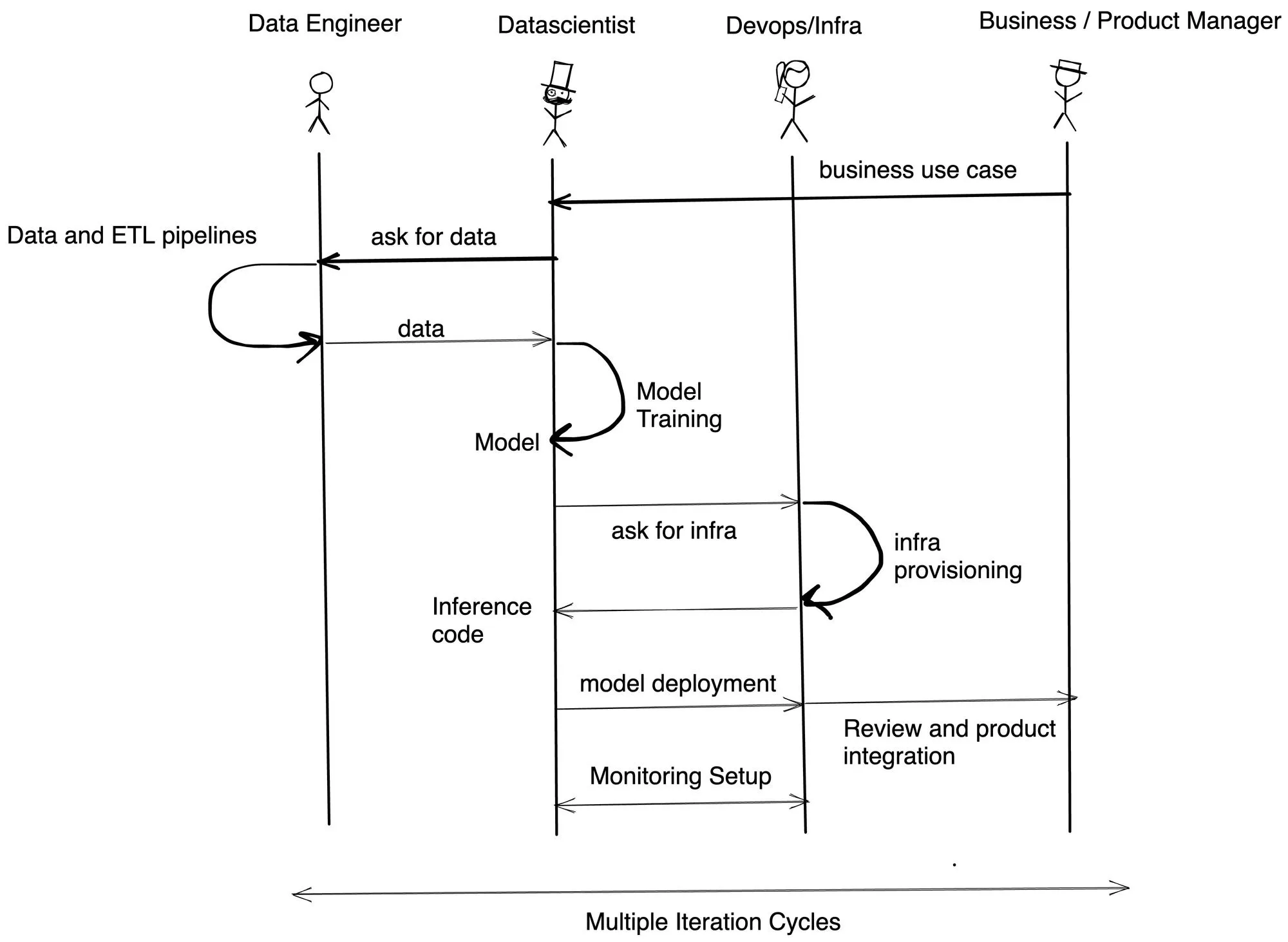
TrueFoundry helps you to reduce the development time by at least 3-4x by empowering Data Scientists to deploy and evaluate the model on their own without reliance on the infra/DevOps team.
With TrueFoundry, the flow is similar to the one below:
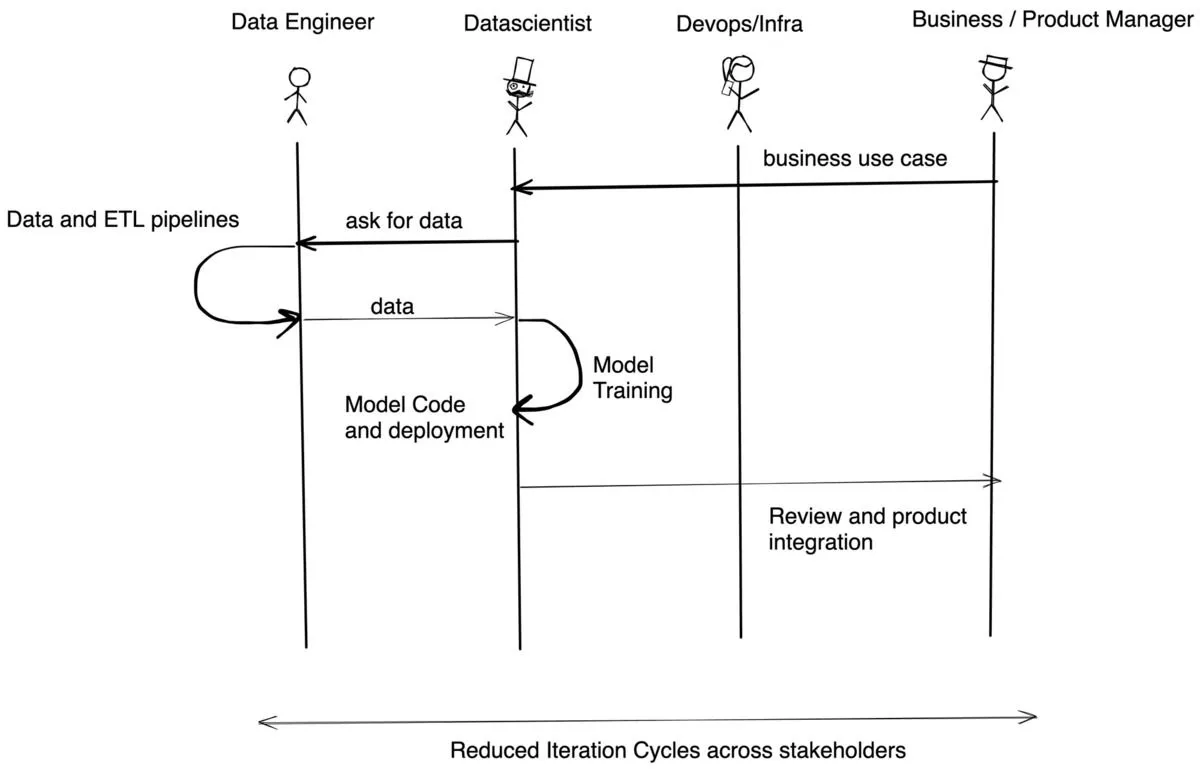
TrueFoundry is Kubernetes native and it works over EKS, AKS, GKE (standard and autopilot clusters) or on-prem clusters. ML requires a few custom things compared to standard software infrastructure - like dynamic node provisioning, GPU support, volumes for faster access, cost budgeting and developer autonomy. We take care of all the nitty-gritty details across the clusters so that you can focus on building the best applications over a state of the art infrastructure.
We provide Python APIs - so you never need to interact with YAML. We do provide YAML support also if you want to use it in your CI/CD pipelines. For e.g, using TrueFoundry, you can deploy an inference api using the code below:
service = Service(
name="fastapi",
image=Build(
build_spec=PythonBuild(
command="uvicorn app:app --port 8000 --host 0.0.0.0",
requirements_path="requirements.txt",
)
),
ports=[
Port(
port=8000,
host="<Provide a host value based on your configured domain>"
)
],
resources=Resources(
cpu_request=0.5,
cpu_limit=1,
memory_request=1000,
memory_limit=1500
),
env={
"UVICORN_WEB_CONCURRENCY": "1",
"ENVIRONMENT": "dev"
}
)
service.deploy(workspace_fqn="tfy-cluster/my-workspace")
TrueFoundry gets deployed entirely on your own Kubernetes cluster. The data stays in your own VPC, docker images get saved in your own docker registry and all the models stay in your own blob storage system. You can read more about the TrueFoundry architecture here.
Kubernetes usually supports autoscaling using HPA based on CPU and memory. However, for ML workloads, autoscaling based on request counts is a lot better in many cases. Another challenge in autoscaling can be the high startup time of models because of large image sizes and model download times. Truefoundry solves these problems by providing container startup time in seconds, caching of models for faster loading and providing faster inference times.
Can we use some open-source LLM models?
TrueFoundry allows you to deploy and finetune the open-source LLMs on your own infrastructure. We have already figured out the best settings for the most common open-source models so that you can train and deploy them at the optimal settings and lowest cost.
We host an internal LLM playground where you can decide which LLMs you want to whitelist for the company developers, including internally hosted ones and different developers can experiment with the internal data. Here is a quick video on same:
Jupyter Notebooks are essential to the Data Scientist's daily development cycle. Running Jupyter Notebooks locally on one's own machine is not always an option because of the following reasons:
We have put in a lot of effort to seamlessly run Jupyter Notebooks on Kubernetes. Jupyter Notebooks on TrueFoundry provide the following benefits compared to JupyterLab or Kubeflow Notebooks:
TrueFoundry provides a model registry that can track which models are in what stage and the schema and API of all the models in the registry.
TrueFoundry allows splitting or mirroring traffic from one model to another. This is especially useful when you want to test a new model version on live traffic for some time before rolling it to production. Truefoundry also supports canary and blue-green rollout strategies in model deployment.
We have put in a lot of effort to make sure we take care of the nitty-gritty differences of the Kubernetes clusters across clouds. Developers can write and deploy the same code in any environment without worrying about the underlying infrastructure. We take care of checking if underlying components of Kubernetes are installed, checking incompatible migrations and informing developers accordingly.
We expose the cost visibility of services to developers and provide insights to reduce the cost. All our current customers have seen atleast 30% cost reduction after adopting truefoundry.
TrueFoundry is an ML Deployment PaaS over Kubernetes built to simplify AI model deployment, speed up developer workflows, and maintain full infrastructure control. Through our platform, we enable Machine learning Teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds - allowing them to save cost and release Models to production faster, enabling real business value realisation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.




.webp)


.webp)
.webp)
.webp)
.png)






.webp)
.webp)