














June 20, 2026
|
5 min read

Published: January 19, 2026
Blazingly fast way to build, track and deploy your models!
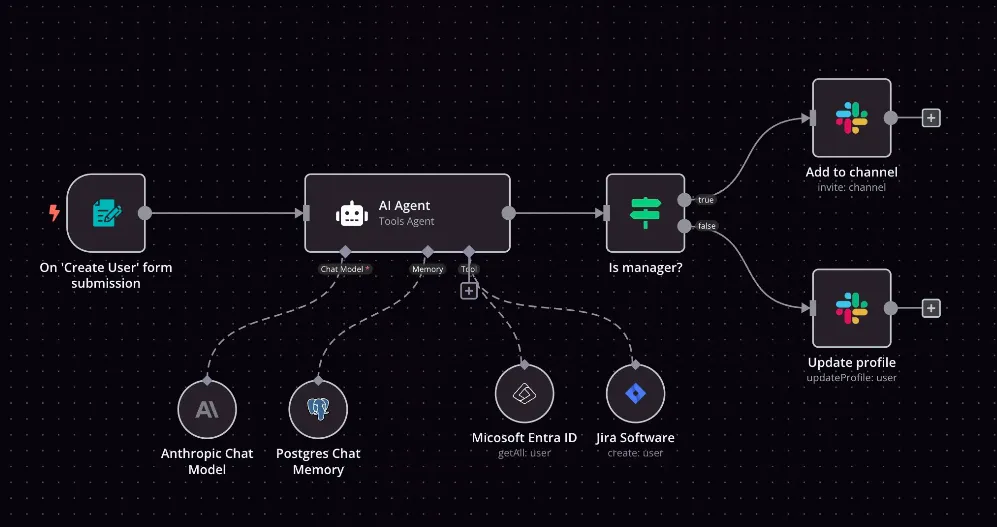
Low‑code builders like Flowise have surged because they’re fast. The drag‑and‑drop canvas lets data scientists and product managers link prompts, tools, vector search, and multi‑step agents - no Python needed. Proof‑of‑concepts ship in hours, not weeks. But when those prototypes start driving real value, the hidden tax shows up: every node calls a different model endpoint, each with its own API key, its own usage logs, and its own line on the company card. Multiply that across teams and experiments and no one can answer the basics: Who called what? How much did it cost? Was it safe?
This is exactly what the TrueFoundry AI Gateway solves. It processes over a million LLM calls a day for enterprises, applying project‑level authentication, per‑request cost controls, latency SLOs, and full audit trails - whether you’re using GPT‑5, Claude 4, Mistral, or an in‑house fine‑tuned model. Teams asked us to bring the same guardrails to Flowise agents. So here is the detailed blog on: Why low‑code agents belong behind the gateway
That’s the same governance we already apply to mission‑critical traffic (>1M calls/day). Adding Flowise simply extends it to your low‑code experiments. For a quick look at Truefoundry's AI Gateway visit: Link
Prerequisites
Set-up in two short steps
You can find a more detailed walk-through, complete with screenshots, in our docs
Once those two fields are filled, Flowise inherits everything the Gateway already does for production workloads:
Want to get started? Sign up for an account here: TrueFoundry no credit card required :), follow the setup steps in our quick start guide, and you'll have a production-ready AI stack running in about 15 minutes. No complex migrations, no code rewrites - just better performance, security, and control for your AI applications.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.









.webp)
.webp)
.webp)
.webp)
.webp)

.webp)

.webp)

.webp)
