June 12, 2026
|
5 min read


Blazingly fast way to build, track and deploy your models!
Enterprises are racing to operationalize AI—but the journey from proof-of-concept to production often gets stuck between two extremes: raw performance and operational discipline. On one side, you need infrastructure that can handle the scale and latency demands of modern AI applications. On the other, you need governance, security, and cost controls to make it viable in the enterprise.
The new partnership between Cerebras Systems and TrueFoundry bridges this gap. Together, they deliver a platform where organizations can run the world’s most advanced models at unprecedented speed, while also ensuring observability, governance, and flexibility.
Cerebras has become known for pushing the boundaries of AI hardware and inference. With its wafer-scale technology and Cerebras Inference service, enterprises get:
For enterprises, this means the ability to finally deliver low-latency AI products—from conversational agents to real-time summarization—without being bottlenecked by hardware.
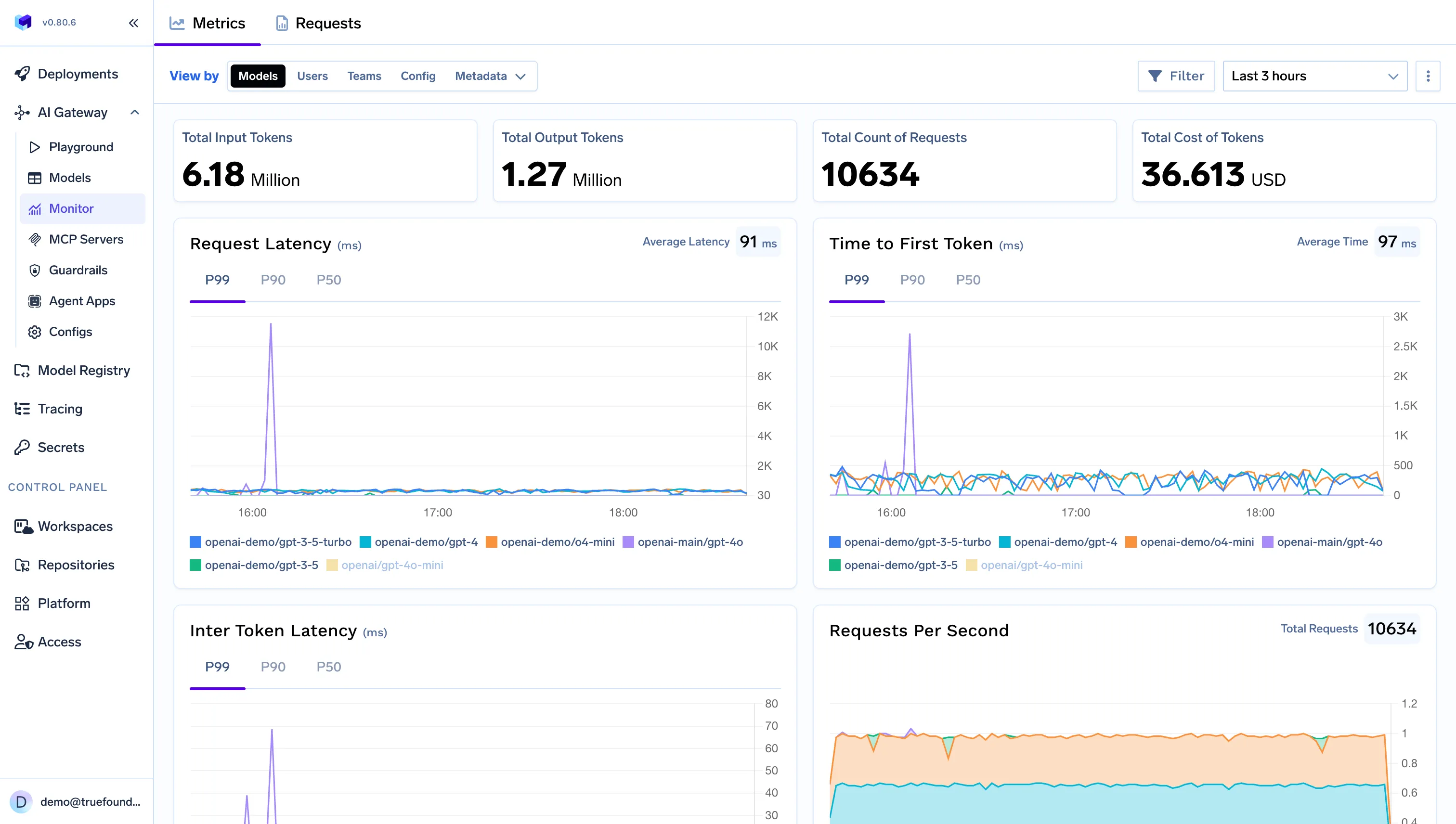
While Cerebras solves the performance problem, TrueFoundry solves the operational one. Its AI Gateway acts as the control plane for enterprise AI usage:
In short, TrueFoundry ensures enterprises can scale AI usage safely, visibly, and predictably.
Bringing Cerebras and TrueFoundry together creates a full-stack solution for enterprise AI deployment:
This partnership marks a shift in how enterprises approach AI. It’s no longer enough to run benchmarks in labs or pilots in isolated teams. Enterprises need:
Cerebras × TrueFoundry delivers on all three.
The Cerebras–TrueFoundry partnership represents more than just an integration—it’s a blueprint for the next phase of enterprise AI adoption. By combining Cerebras’ unprecedented inference performance with TrueFoundry’s AI Gateway for governance and control, enterprises can finally run AI workloads that are not only powerful, but also production-ready.
For businesses aiming to bring AI out of prototypes and into mission-critical workflows, this collaboration unlocks the missing piece: a platform that is fast, governed, and future-proof.true
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.





.png)